I recently talked about the idea of testing being part geometry and part topology. What might not have been conveyed through that post, however, is how powerful the notion of shape is. What’s particularly interesting about shape is also how we can determine shape by how we choose to observe something. And testing is very much about observing. So let’s dig into this particular rabbit hole.
Testers have to observe the shape of bugs and the circumference of their test coverage that finds those bugs and even the surface area of where and how bugs might manifest. Hmm. Does it sound like I’m stretching to make a point there? Well, what I’m going to show here, at least hopefully, is how thinking about shapes in general terms is one way to condition the mind to think about these ideas in more abstract way, such as when bug hunting. (With all due cautionary elements from my bug hunting focus for testers somewhat understood.)
Intuition for Shape Thinking
Bugs often take us from one abstraction to another. We have a description of a bug — the formula for how to find it, if you will — and we have how the bug actually manifests in the application. So let’s hone our instincts for this. This also, and not coincidentally, is the case with requirements. Requirements describe something that ultimately becomes a set of functionality that works in particular way.
We have, here, different “shapes” to things. Consider the following:

These are the basic equations for circumference, area, surface area and volume. Regardless of your facility with math, I’m willing to bet that just by looking at those you can get a sense that they are in some way related. After all, we’re seeing π and r all over the place.
This is where being able to visualize what we’re being told or shown is very important. To wit:
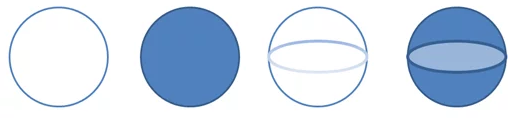
Well, that’s nice, right? Now we have some visualizations that go along with our formulas.
This could be akin to a statement of the bug versus how the bug actually appears. Or it can be our description of a requirement and how that requirement is actually implemented. The formulas are no more and no less a shape than the visuals; they are just a different way of expressing it. Just as how code in a certain configuration manifests as a particular way the application does (or does not!) work.
And, if we’re paying attention, we see some interesting aspects here.
Intuition for Shape Similarity
First, we can see that a circle and a sphere can appear to be the same shape when drawn visually. But, of course, we know their dimensionality is different. This is a key thing testers deal with all the time: the approximation of the thing and the actual thing itself. I sort of talked about this a bit in the dimensionality with testing.
Second, we can see that as we get to a sphere, the realization dawns that said sphere is really just made up of a bunch of circles. Or discs if you prefer.

But here’s where we start to really harness the power of visualization and see similarities. We can see that each individual disc or circle is really just a bunch of rings put together.

What that’s actually doing is showing us how we go from a circumference to an area. Mathematically speaking, we’re figuring out how to determine the size of a shape that is consistently curving. Even more importantly — and I will come back to this point — What we’re doing looking at an outcome — a circle, with a circumference — and moving back to how that circle could have been created.
This is very much akin to finding the “shape” of the experiences we provide our users. Instead of starting at the beginning and trying to work everything out step-by-step, we might instead start at the outcome and work our way backwards, determining how the outcome will be delivered.
We can take this even one step further, however. And this is the part that often isn’t as obvious. Let’s start with this:

You can imagine that we have sort of “unrolled” each individual ring from our circle and created a line out of it. Here we’re just taking all of our rings and we can imagine stretching them out so that they are straight lines. Great, but what’s the point of that?
Certainly a series of lines like this can be easier to measure, no? First let’s realize the shape this gave us:

A triangle!
We have all those rings and now incrementally we can probably measure each. For example, mathematically, we could get the circumference of each one:

The height of each ring/line depends on the original distance of the given ring from the center of the overall circle. So if you have a ring that’s, say, four inches from the center, that ring/line would then would have a height of 2π × 4 inches. Thus the height of the largest ring is the full circumference, which is 2πr.

At this point you might be thinking, “Okay, I didn’t come to this post to read about math.” But abstract away the math for a bit and just look at what happened here: we got to a point where we were capable of measuring something in an easier way than we could before. A triangle is much easier to measure. Why? Because what you have is a base of the triangle and a height of the triangle. Thus, and just trust me on the math if it isn’t your thing, this means we have 1/2 base multiplied by the height. So we have 1/2r × 2πr.
And that gives us what? Well, that gives us πr2.
Look familiar? That’s the formula for the area of a circle!
Similar approaches work to go from area to surface area and then from surface area to volume. I can’t stress enough how powerful this kind of thinking is. And it is these very mental abstractions that we go through as developers and testers as we work with code and applications to deliver experiences to users. Just as how our brains can do calculus when trying to catch a ball, our minds go through shape-based thinking when we work with complex environments.
Shapes Provide Multiple Ways of Viewing
One point regarding the above is that we revealed a relatively simple, easy-to-measure structure within a curvy shape. That’s at the literal level. But abstract that now to your day-to-day set of activities.
We take something complex (say, some specific actual feature of an application) and we reduced it to something that we can measure (a requirement that describes that actual feature). And thus, in a way, have we also described a potential bug. The potential bug would be something that doesn’t operate correctly given the thing we described (requirement) and the thing as it is (actual feature).
As we worked through the above together, along the way a subtle point was introduced. We saw how to take something and break it down. How we break it down — the shapes we apply — can guide how we look at something. Obviously we can take our big picture view of the circle and say its made up of lots of rings.
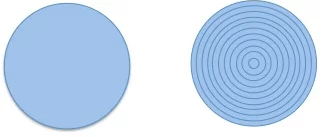
And we can imagine “scaling up” our circle accordingly. Perhaps this equates to our test coverage as we expand the area of where we test.
But we can also apply different shapes to this testing:

We can start to categorize things by the area we are considering.

Maybe this is ultimately what becomes the surface area of our regression testing if we make some assumptions about what testing we should be running given a certain set of changes to requirements.
But notice what’s happening there? We are choosing how to observe something. We are being guided by the shapes we construct. The question is often whether we are aware of the shapes we construct. If we’re not, that obviously would preclude us asking if we are using the right shape in the first place.
We Get It! You Like Shapes.
Yes, but there is, I truly believe, something interesting happening here as we take our thinking down this path.
Another point to note here is that we came to the realization that a circle and a set of rings were really the same thing. Just as a sphere is really the same thing as a series of circles (discs), a circle (disc) is really the same thing as a series of rings. This can help reinforce my discussion on the joy of testing where I talked about how going in circles is the same thing as riding on waves.
A somewhat subtle point of the above is that the sphere-as-circle and circle-as-ring concept makes sense as a “time lapse.” You can imagine the one shape sort of growing, incrementally, by or from the other shape. This idea of temporality matters very much in development and testing. Things that we build evolve over time; it’s where the complexity actually comes in. Our ability to find bugs and reason about requirements is often predicated upon concerns of temporality, such as temporal durations between when a bug was introduced and when we actually got a chance to find it. Requirements can become convoluted when there are large temporal durations between given increments of a feature building up.
Now I keep using the term “incremental” or “increments” here. And that terms is actually part of the problem.
Incrementing … Or Iterating?
There is the concept of being iterative (usually good) and being incremental (usually bad) in the context of feature development.
A lot of people would tell you — and I happen to agree — that the goal is to avoid a purely incremental approach. For example, let’s consider:

Here we’ve framed the desired outcome as a shape. Okay, yes, technically it’s a painting and thus a whole bunch of shapes. But what did we just learn above? Smaller shapes ultimately make up one big shape. Here we’re just ramping up the complexity a bit.
Here the problem is that the outcome — the shape — is being envisioned as some fully complete thing. This leads to an incremental strategy:
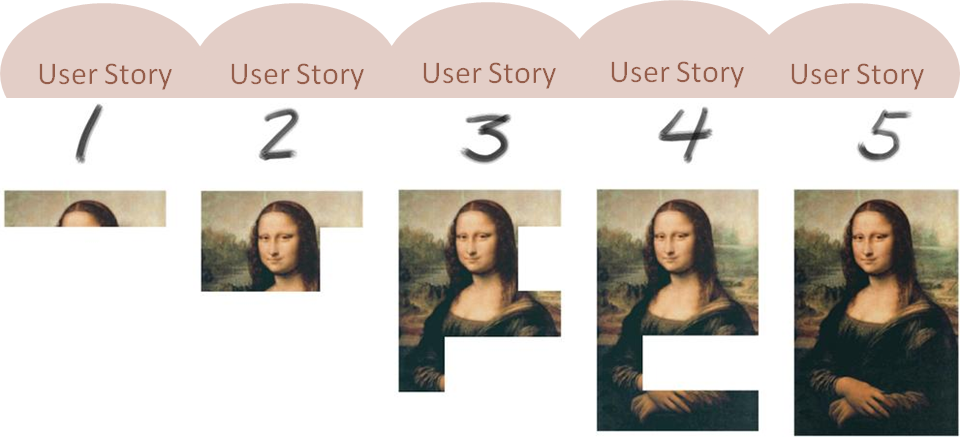
Looked at a certain way — and shapes are all about looking at things a certain way, right? — what this means is you never actually deliver a viable outcome until you deliver the full thing that you imagined. You build it up in increments, which focuses on outputs and not outcomes.
The goal with shape-based thinking is thus to adopt an iterative approach.

Here the outcome is envisioned as just that: an outcome. That outcome is not stated as some completed thing (and thus not really a shape, notice) but rather as a benefit that is desired. This leads to an iterative strategy:

Here you can potentially be delivering a viable outcome at all points, while also giving yourself the freedom to gather feedback and determine how the vision may have to change.
Our shapes from before can still be front and center here, right? Consider:
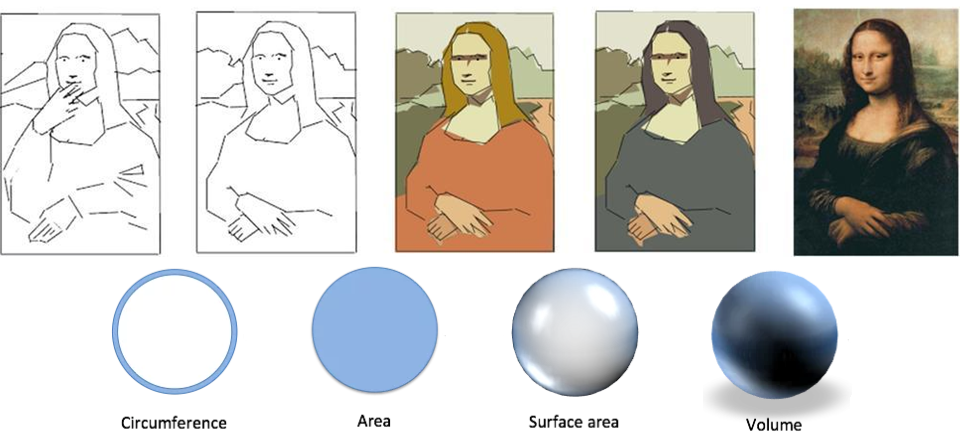
Notice, in the series of paintings, how the hands change position, for example. Notice how the background changes a bit. But, overall, we end up with the outcome we desire. And nothing says we had to end up at stage 5, as it were. Perhaps ending up at 4 would have been good enough. In other words, maybe we didn’t need that full volume and could have stopped somewhere around the surface area.
Yet, in reality, how many times have you been in situations where features end up getting worked on only to be subsequently dropped entirely, removed once in place, or become gutted? The extent to which this happens, and the regularity by which it happens, is a good measure how much — or rather how little — people are adopting a shape-based way of thinking. And shape-based thinking is all about outcomes. And testing, ultimately, is all about outcomes as well.
Limits to Seeing Shapes
Let’s consider yet another variant of this thinking.
Consider that when we look at something we can see its shape. The reason we can see the object at all is because we use light to view it. But the reason that we can specifically see it’s shape is because of how the light we use to see it bounces off of the object.

This works really well for just about everything we care to observe.
But as we wanted to explore smaller and smaller things this mechanism started to fail us a bit.

We had to develop tools to help us, like the microscope. And we’ve had to steadily improve the design of these microscope to see smaller and smaller things, such as by inventing an electron microscope. So notice that our ability to discern the “shape” of things was constrained. It wasn’t just a matter of if we were looking or not; it was a matter of exactly how we were looking. We were essentially crossing abstraction levels.
Even as we improved our testing tools and thus our observability mechanisms, we knew that this particular path of exploration would come to an end. This was because we determined that there was a fundamental limit to what it’s possible to see with light. Even using a microscope, you really can’t see anything smaller than about a millionth of a meter, which is about one hundredth of the thickness of a human hair. This has nothing to do with our ability to make better lenses but rather because waves of light simply don’t bounce off such small objects.
This means we have to consider our detection mechanisms. Perhaps read that as: we had to consider the tools we used to support our testing that were designed to allow us to look at the shapes of very small things. The important point here is that what you are trying to observe may be something that a given test technique simply will not help you with.
Think about this in terms of, say, testing at the appropriate abstraction level. Maybe I’m testing an application with a nice UI that, behind the scenes, has an API that is utilizing gRPC endpoints to to query a service that will in turn read data from a database. Eventually that data will be displayed by the UI. But notice the abstraction levels here? I might be able to only “see” the UI part but I can provide detection mechanisms at these other layers to gain some observability.
But will I still see the “shape” of things directly? Or do I have to rely on indirect observations?
Observing Shape by Indirect Means
So you probably know the situation where you have a bug somewhere in the application you’re testing. These bugs will have a shape of sorts. But it’s not just sitting their announcing “I’m a bug! Here I am.” So the bug is sort of hidden behind the curtain of the application’s interface, such as the one I described above. And you fire tests at that interface to find the bug, much as our electron microscopes fire certain kinds of waves at objects in order to resolve different details.
So let’s go for an analogy here.
Imagine some object that’s sitting on the floor of a room. This object is surrounded by a curtain that hides its shape from you. You want to find out what the shape of the object is. And you can’t move the curtain aside and just take a look. Your only test equipment is a whole bunch of little marbles. So all you can do is sit there rolling the marbles across the floor, under the curtain, where they will collide with whatever is behind there.
By looking carefully at how the marbles bounce out and, further, by sending the marbles toward the object at different velocities, you can get an impression of what the object actually looks like. Meaning, you can start to determine its shape. Say there’s a box behind the curtain, that’s situated at a 45-degree angle. In that case, the marbles will rebound exactly to the left or to the right.
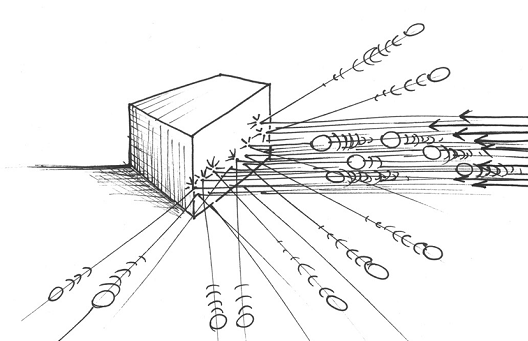
Running a relatively few set of tests will help determine the shape quite quickly. The basic technique is the collision and the test observation would be the angles of the marbles.
But what if the shape is a bit more complicated than that?

Here, obviously, the test technique would be the same but the level of work involved to determine the shape is a bit more problematic. What this would require is a slightly more sophisticated model of how to determine the angle of deflection. And, perhaps, it involves a slightly more refined test technique of using marbles.
Also notice something interesting here. I implied, and then assumed in my examples, that the object was something big enough that the marbles would act in a way such that we could use them to determine shape. Meaning, they would bounce off. But if the object was, say, a piece of dust or maybe a thin string or maybe a feather, it’s quite possible the marbles would not have bounced off of it at all, but rather just rolled right over it and out the other end. In that case, you might end up assuming there is nothing behind the curtain at all!
The Dynamics of Testing for Shape
There’s a corollary above with what I talked about regarding abstraction levels for tests, which is that you can (and should) try to test at the appropriate abstraction level. And one way to look at this is to keep our tests tiny. Imagine, in the above scenario, if instead of marbles I used, say, a bowling ball. That would have actually been quite a bit less effective in telling me what I wanted to know about shape.
So what are these “tiny tests” I speak of? Well, these are the unit level (possibly) and the integration level (definitely) tests. These kinds of edge-to-edge tests put a great deal of concentrated energy against the shape of the application and its bugs, whereas larger scale end-to-end tests, while still valuable, distribute the energy a bit more. The end-to-end tests help us get a shape, for certain, but they also come at a fairly late time and removing a lot of details.
This also lines up with something I talked about previously, when discussing test shapes, in terms of the following dynamic:
- Test simplicity is best focused on in unit tests.
- Production faithfulness is best sought with integrated tests.
As I stated in the post, that interesting dynamic suggests the following:
- You should try to increase production faithfulness in unit tests.
- You should try to increase test simplicity in integrated tests.
Those broad strokes of looking at things is what leads me to promote the diamond shape for testing:

This would be in contrast to the standard test pyramid shape.
And the fact that we can call the shapes by names, such as “diamond” and “pyramid”, gets into another way that shapes help us, which is by providing a taxonomy. This taxonomy is something I’ll explore in a follow on post to this one.
Was This Really Relevant to Testing?
How we test something speaks to how we observe it. How we observe it speaks to the means by which we choose to do so and the level of detail we hope to get. Getting a certain level of detail is what allows us to reason about things, not just the things themselves but how they interact with other things. Everything has a shape in some kind of space. That space will be situated within a particular abstraction stack that we have to move along.
Moving along that space involves moving in time as well and, as I stated (perhaps a bit obviously) in testing and the nature of time, time and space provide the context in which history happens. In this case, the history of our applications: how they come to be, how they evolve, how bugs get introduced, how features grow and change, and so on.
All of that history forms the persistent shape of testing.
