A lot of testers are talking about how to use artificial intelligence (AI) or machine learning (ML) to be the next biggest thing in the test tooling industry. Many are in what seem to be a lemming-like hurry to abdicate their responsibilities to algorithms that will do their thinking for them. Those same testers, however, often have absolutely no idea how to actually test such systems in the first place. So let’s dive into this a bit.
Before we get started, here’s one of my key points: why are some testers so willing to trust the act of testing to algorithms and agents that they themselves don’t even know how to test? On the face of it, it’s ridiculous. Yet you have many tool vendors out there touting their own “AI” (which it’s usually not) or extolling the virtues of AI and ML (even when they have barely an inkling of the technology, and are just hopping on the bandwagon to sound relevant). That said, on the other hand, you have a professional test consulting industry — individuals or companies — complaining about AI and ML and yet they’re not actually able to demonstrate what they are complaining about.
Mind you, I don’t think there’s anything wrong at all with looking at how these technologies can help augment and support testing as a discipline just as I absolutely believe we have to be cautionary about all the alleged promises of the technology. I happen to think this is a fascinating area of research. But let’s first make sure we actually
understand those technologies and that we can apply our testing discipline to them and can articulate them via demonstration.
I tried this to some extent with my
AI series and my
ML series. Here I’ll focus on a specific example to bring forward some points about a testing tool “doing” AI of some sort while also looking at how you might test that tool. The cautionary part here will be that if you find you don’t understand how you would test this tool, maybe you shouldn’t be so quick to want to use it for testing.
This will take a bit of context and exploration so if you want to give this post a shot, I would recommend settling in for a bit.
A Flappy Approach
What I’m doing to in this post is give you a working implementation and some ideas to give a start on understanding some of the concepts and the logistics. I’ll do this with Flappy Bird, which is a very common context in which to test out AI and ML.
When I say “very common,” you can see articles like
Using Keras and Deep Q-Network to Play FlappyBird (with
associated repo and a
simplified implementation). You can also check out:
Machine Learning Algorithm for Flappy Bird using Neural Network and Genetic Algorithm (with
associated repo. You might also check out
Using Deep Q-Network to Learn How To Play Flappy Bird.
Incidentally, feel free to try your skills at the game:
http://flappybird.io/. You can also try the
TesterStories version, which is perhaps a bit easier to play. But that “easier to play” (for a human) part does actually present a huge problem for an artificially intelligent learning agent. Specifically, it would be very hard to get an agent to train on that browser-based version, but less so on the flappybird.io version.
TESTER! Think about why that is.
In this post, I’ve written a small “testing tool” and incorporated it into how an AI agent trains against a Flappy Bird implementation. I’ve used a simple table-based approach (Q-Learning) and a small but effective neural network approach (DQN). Both of these approaches, arguably, would be valid ideas for building an AI-based testing tool.
How Is Flappy Relevant?
What you’re effectively doing with this game is probing a problem space and trying out various scenarios — call them test cases, if you prefer — that interact within that problem space. For an AI tool acting as a testing tool, that means the tool must be able to recognize the problem (“see it”), learn how to carry out actions in the problem space (“understand it”), perform those actions (“manipulate it”), gain feedback, which you can treat as test results (“observe it”), and then determine if enough feedback has been received to make a determination of whether the quality is good enough (“reason about it”).
The quoted elements in the parentheses are a simplified way of describing what a human would do in the same context.
If you haven’t already spent time playing the game and gotten good at it, this game can be a little difficult to play. Try it out with one of the implementations I provided above. There are a couple of aspects here. First is simply learning to play the game at all. Then there’s learning to play the game well. Meaning, to actually get good at it. As a tester of the game — and as a tester using an AI tool — you also have to decide when to stop testing. When have enough test cases been run? But if this is an AI tool, you can’t program the answer to that question in. It has to figure that out on its own. And that leads to some interesting questions and problems.
Test Tool (Of The Future!)
So let’s say you’re in a company and one of its great new inventions is a learning type system, composed of a machine learning layer wrapped around an artificial intelligence agent. This agent should be able to look at a UI and figure out how to interact with it. Then once it has that figured out, it should try to find any issues that it can with the UI by essentially generating test cases and executing them.
The first part is often the hardest: getting your AI testing tool to actually recognize an environment and operate within it. To test out this generalized agent, Flappy Bird is chosen as a test case. Does that sound like an odd approach? Actually, there’s a reason that Google’s DeepMind is often touted for playing Atari 2600 games or why AI courses in many universities use demonstrations with agents that can play games like Starcraft. Or why learning agents in NP-Complete problems use Tetris as their base.
What we want is to build a learning agent that, in the case of Flappy Bird, can learn to play the game and, ideally, learn to play it as long as possible. That will prove to us that it actually has learned it as opposed to just gotten lucky. Since the game itself — by which I mean its interface and how to interact with that interface — is fairly simple, the tool should be able to determine if we have any bugs in the game as well.
If we find this works, perhaps we can generalize our learning tool to other applications. Perhaps
any application! And then finally world domination will be within our sights!
The Flappy Prototype
I have an implementation for you, ready to go. This is called
Flappy Tester. If you want to run it, you will need Python 3 on your system and a few dependencies. If on Windows, make sure you have a 64-bit version of Python. Those dependencies are listed in the
requirements.txt file. Ideally you can just run this to get them:
pip3 install requirements.txt
Incidentally, I’ll note that when using Python, all of us are using pretty much the same core implementation of the Flappy Bird game, which is the
Flappy Bird Clone using python-pygame. I’ve cleaned up some of this code in my own implementation.
The Basis of the Flappy Prototype
What we’re really focusing on here is reinforcement learning (RL). Here’s a schematic of what that means:

Why might you use that for a testing tool that is based on AI? Well, the goal of this kind of approach is to consider sequential decision making. If someone was going to build a testing tool based on some algorithmic approach, reinforcement learning would be a good one to consider because it models how humans learn: by trial and error, that leads to a good model of the world, that is reinforced by rewards taken due to actions.
Most test tool vendors immediately jump to supervised learning or unsupervised learning as their go-to approach. And there is viability in these, to an extent. But a key aspect is that an RL approach allows you to consider delayed rewards. We’ll come back to delayed rewards a bit later but it’s really important in testing for value, as opposed to just testing for correctness.
Test Tool Learning Flappy
First, let’s think how you would test Flappy Bird yourself as a human. As with any application, for any actions taken against some user interface, you have to consider the possible states that the interface can be put in and the possible actions. Those actions are the things that can be done to interact with the system. Those are the things that test cases would exercise and observe. The observations would be the new states created as the action was carried out.
TESTER! Think about that for any application of reasonable complexity, such as where there are a lot of actions and states. You’ll come to see — if you don’t already know it — that Flappy Bird is an incredibly simple example to run a test tool against. I did that purposely so you could have a barometer for scaling up your thinking.
In our flappy context, each state can be defined using three independent parameters:
- Horizontal distance of the bird from a pipe.
- Vertical distance of the bird from a pipe.
- Vertical speed of the bird.
There are only two possible legal actions: to flap (accelerate) or not.
That’s it, really. Three states and two actions. Thus this is a very simple system.
You also have to consider the rewards. These are things that, as a tester, you might treat as good or passing results. But you can also have a negative reward, which you might treat as finding a bug. But, in this case, it’s more about how the AI agent knows whether it is learning to interact in a way that maximizes the good and minimizes the bad.
This gets interesting because learning agents — and a test tool learning agent — have to have some way to determine not just that they
are learning but that they are learning
effectively. In my
Pacumen example, the Pac-Man character lost a point each turn. This was a negative impetus to make sure that the RL algorithm behind the Pac-Man agent had some reason to not just learn, but to learn effectively.
As far as rewards, in our immediate context, these are likewise simple:
- Colliding (with ground or pipe): negative reward
- Not immediately hitting a pipe: minimally positive
- Crossing the pipe intersection: positive
So what’s the agent’s goal here? Clearly, to maximize the long term reward. That would mean achieving a very high score. In a test tool context, this could be framed around the positive rewards (find no bugs) or the negative rewards (find bugs).
TESTER! Whoa! Lots to unpack there! What are the equivalents of positive and negative rewards in testing? Is finding a bug a negative reward? Well, not really, right? After all, that’s part of what we’re looking for. But what if we don’t find a bug? Is that a positive reward? But — wait! — if we treat that as a positive reward, and a learning agent maximizes positive reward, does that mean the agent will start to avoid finding bugs? There are many related questions we can ask about this. Think about how you would incorporate that into a testing tool.
Really think about it. I’m going to have a non-Flappy Bird example near the end of this post for you to consider as well.
So let’s try this all out.
Test Tool Q-Learning Approach
In the case of Q-Learning, what’s happening is that the agent is essentially building up a large set of what are called Q-values. Here’s a rough schematic of what that looks like:

I mention Q-Learning because that’s one aspect of what AI-based testing tools might utilize.
With my code base, you can see the
environment_loop method in
flappy_ql.py, which is commented to some extent to give you an idea of what’s happening. As far as the Q-values, look at
update_q_values in either
q_learning_agent.py or
q_learning_agent_greedy.py. What we’re doing here is putting place a
policy for how to act.
Basically, after every time step, the agent stores the transition — from one state to another — into a collection of moves, which ends up being a list of all the transitions of the current game. Combined with the rewards, this corresponds to the main training function to update the Q-values.
The state space of Flappy Bird is essentially being discretized in terms of horizontal and vertical distances from the pipes. This allows for much faster learning but it’s also why I said earlier that my browser-based game would be very problematic for an AI agent to learn in any sort of reasonable time frame.
TESTER! Consider what I just said there. The application was simplified in order to ease learning. This is a tricky thing to do when you want to test the “real” thing. What ends up getting tested is an approximation of the actual application in many contexts. In the case of the Q-Learning example, I kept the approximation pretty true to the actual game.
A key thing is that AI and ML often have to train on a system. The training is how the AI or ML agent learns to “understand” (note the quotes) what it is dealing with, how to take actions, how to recognize rewards (negative and positive), and how to build up a policy for how to act in any given situation that it may encounter with the problem space (application) it’s dealing with.
Run the Q-Learning Test Tool
To try this out, you can run Flappy Tester by training a model.
python3 flappy_ql.py train
Consider every “episode” to be a test case. This will create a
model.txt file. Thus if you want to train a fresh model, you could delete that file. Note that in order to write the file, you have to actually close the Flappy Bird application. Don’t CTRL+C at the command prompt.
Once you have a model file, then you want to against that model. You can do that like this:
python3 flappy_ql.py run
Test The Testing Tool
So as a tester, how would you go about testing the AI? Keep in mind that we want to trust this tool to test for us, right? But to trust it, don’t we have to know that it will do what it should? Otherwise, where is my trust coming from? Let’s consider this. What are two things you could immediately focus on, as a tester, in order to see if this AI tool is working?
TESTER! Stop reading right here and think about this for a bit. If you have trouble coming up with an answer that should at least caution you against trusting such a tool in the first place.
What are two things that are probably the most obvious, low-hanging fruit, such that changing them would likely tell you something useful about how the AI-based test tool is working?
Hopefully you came up with this:
- Change the reward.
- Change the training time.
Now, what would you be observing as part of changing those test conditions? Meaning, what would change — as an output — such that you could determine how well your inputs were allowing you to understand the system?
This should be pretty obvious:
So what might a test result — a conclusion — tell you about how to test your own testing tool? A few things might be this:
- A more relaxed policy should provide good results but with a lot of training required.
- A harsher policy should provide better results with much lesser training.
This leaves open what “relaxed policy” and “harsher policy” mean. It also leaves open what it means to recognize “good results” and “better results.” As a tester, you have to have some idea of how to make those things specific. But, keep in mind, the AI tool has to do that as well.
So my “Flappy Tester” tool — an AI-based testing tool — will execute when you run a “train” version of the command. Now, here’s a key question: how long will it take for the Flappy Tester to get good? Will it ever? And if it ever does get good, what will it be able to tell you? How would it find bugs? How would it recognize a bug? And, beyond even that, will the Flappy Tester be able to tell you whether or not the game is too hard or too easy for a human? That is, after all, part of what makes up quality.
Aside: The Algorithms and the Data
Anyone touting an AI-based solution for testing does need to understand that whatever system you use, there will be some sort of algorithm behind the scenes. And that algorithm will be consuming data. Often lots and lots of data. I don’t want to dig too much into this here but let’s consider this from a Q-Learning perspective.
Q-Learning is basically about evaluating actions. Or, more specifically, about how to evaluate what action should be taken given a certain state and the possible rewards for taking the action in that state. That’s all summed up by a nice little equation:

Now, you might say, “Jeff, you idiot, how am I supposed to be able to reason about that? I don’t know that formula!” Sure, but there it is! I just gave it to you. You might have worked in a company that has many algorithms, such as finding parking spaces, determining how to deliver food in the most efficient way, calculating cost drivers for clinical trials, calculating derivatives for hedge funds, providing loans for people based on credit calculations, etc.
Even more to the point, you could argue that Q-Learning approaches would have a lot to say about how a testing tool based on AI or ML would work. The “Q” in Q-Learning, after all, stands for “Quality” and it’s about taking a given action of the best possible quality given a particular circumstance consistent with the knowledge that you currently have. But to do that, the agent has to search a large landscape of possibilities which amounts to executing a large a number of tests.
Regarding that equation, if it helps, consider this slightly annotated version
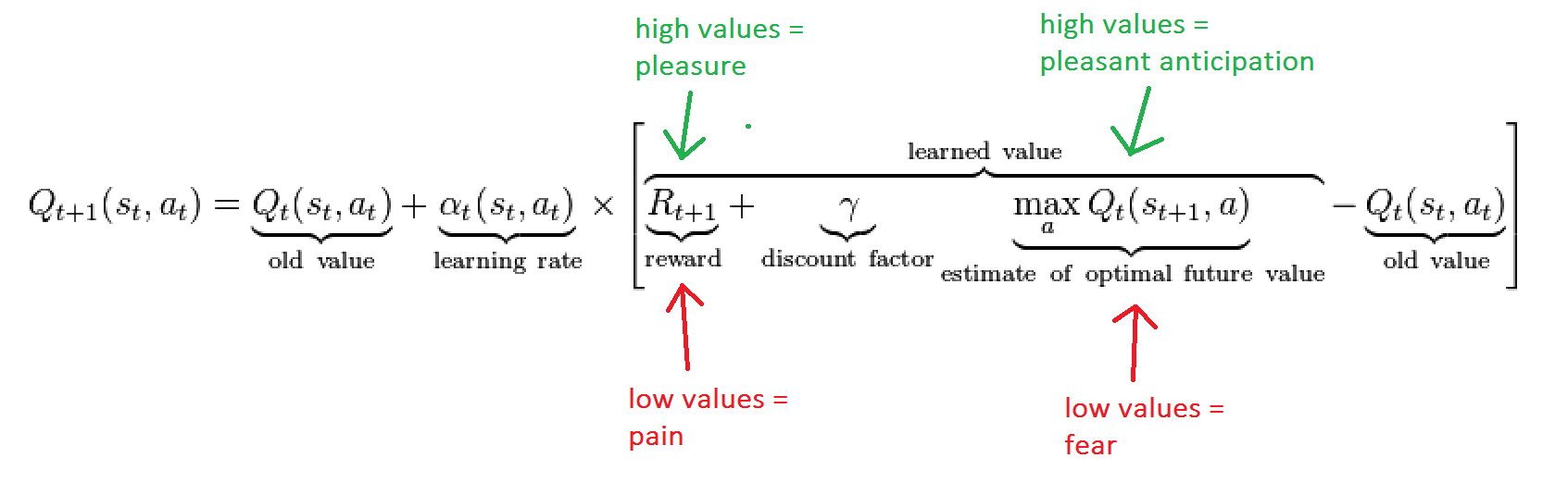
So low values of Rt+1 equal bad experiences (bugs?); high values equal good things (no bugs?). Similarly, low values of the max() part of the equation equals fear (bad); high values mean anticipation (good).
To help you even more, here’s an annotated version of the equation if you find this helps:

My only point here in showing you this is that you have to understand the basis for how an AI-based testing tool would be utilizing an algorithm and what the inputs and outputs to that algorithm would actually mean. This gets even more complicated when you introduce neural networks.
Test Tool Neural Network Approach
You’ll come across a lot of topics regarding “deep learning” and many would argue that such an approach would be necessary for a test tool that is based on AI. Here I’ll scale up Q-Learning slightly by using what’s called a DQN — Deep Q Network.
I chose this because here the Q function — what determines an action of “quality” — can be represented as a neural network. This approach takes the state — in this case, the last four game screens stacked together — and the action as input, returning the corresponding Q-value.
Looking at the
dqn.py file, you will see that this is a simple but effective convolutional neural network for a higher level of feature learning during training. You’ll also see a
process method and the comment there indicates that the input from the game is converted from rgb to grey-scale and the resulting image is resized from the normal 288×404 to 80×80. The intensity levels of the image are also stretched or shrunk and the pixel values are scaled down to (0, 1). This is a much more extreme version of the approximation that I mentioned earlier.
You’ll also see the
flappy_dqn.py, which is similar to what you saw for Q-Learning but I purposely kept this file more uncommented so you could explore it on your own, looking for similarities and differences, should such interest you.
Run the DQN Test Tool
To try this out, you can run Flappy Tester by training a model, similar to what you did for the Q-Learning approach.
python3 dqn.py train
As with the other approach, consider every “episode” to be a test case. This will create a
model.h5 file. The .h5 part is a binary format that encodes the model in a much more compact form than the text files used with Q-Learning. As with Q-Learning, try it out. Train the model and then run against your model like this:
python3 dqn.py run
Of course, that leaves open how much time to give it, right?
Test The Testing Tool
First let’s talk a little about this approach.
The Neural Network Approach
The problem here is that due to the stochastic nature of game play, approximating Q-values using non-linear functions in a neural network is not very effective. There are two ways to deal with this and it’s arguable that a test tool based on AI would have to consider these, which is why I’m even going down this route. And that’s the case because many applications are going to be non-stochastic where these ideas would be much easier to implement.
First, let’s consider
experience replay. This is a concept that can be understood as a kind of fixed memory with a particular size, from which random small “batches” of the memory are sampled that act as input for the neural network. This helps in breaking the similarity of continuous training samples, ensuring some sort of diversity which helps to drive the network, just as it does a human brain. I should note that this replay memory also makes training process similar to supervised learning.
There’s also the famous
exploration vs. exploitation aspect to consider. This distinction is a productivity strategy used in learning algorithms, essentially to decide the iterations spent on exploiting a currently learned model (“doing what it already knows how to do”) versus exploring other new possibilities (“trying new things to learn what they do”).
TESTER! I bet that sounds familiar, huh?
In the testing tool I provided here, I’ve followed the basic design principle which is that the agent tends to perform exploration in which it tries various actions and observes rewards for these actions. The idea is that as a Q-function converges (meaning what it expects for quality and what it actually finds), it returns more consistent Q-values and thus
the amount of exploration decreases.
Q-Learning, without the DQN, incorporates the exploration as part of the algorithm. However, this exploration is what’s called “greedy.” What that means is that it settles for the first effective strategy it finds. Which certainly won’t be the best and may not even be good. And, as testers, we know that’s not a good approach. But how does the AI-based testing tool come to “know” that? And what does it do about it?
A simple and effective fix to this problem is to introduce an epsilon parameter which determines the probability of choosing between exploration or exploitation. Exploitation is called the “epsilon-greedy policy.”
Test Parameters of a Neural Network
Okay, so finally, how you would test this part of the AI tool, given that the states and actions of the game it relies on are the same for the Q-Learning based test tool? Meaning, just as I asked you how to test the Q-learning version to trust it, what would you have to consider for testing the DQN version?
There’s a few things to consider and here I’ll just give you the answers because it’s not as easy to reason about as the Q-Learning.
First would be the replay memory. As I said, this is the number of previous transitions (moves from state to state) to remember. This would be like modulating how much a human brain could remember or, at the very least, how much it could reliably recall. That notion of recall is critical when testing for consistency. (I talked about that and showed an example in
The Art of Attention to Detail in Exploratory Testing.)
You might also consider something called the
discount. I haven’t talked about this much here although if you looked at the Q-Learning equations above, you saw it mentioned. The discount is basically he decay rate of past observations. It’s asking how important immediate rewards are to future rewards. That has a huge corollary with how testers sometimes like for correctness at the expense of value.
Finally, you might consider the epsilon parameter I mentioned and varying that a bit. In the dqn.py file, you’ll see
explore = 3000000. This amounts to the number of frames (of the game) over which to anneal epsilon. Uh, whatever
that means, right? Annealing refers to a step decay where the learning rate is reduced by some percentage after a set number of trainings. So basically you start with a relatively high learning rate and then gradually lower the learning rate during training. But how “gradually”? Therein lies a key question of how you, as a tester, would test your AI tool.
The goal of progressively reducing that epsilon parameter — particularly in a epsilon-greedy policy — is to move from a more explorative policy to a more exploitative one over time. This step-wise reduction only make sense when the agent has learnt something, i.e., when it has some knowledge to exploit.
To test this idea out relative to the other two approaches, I do have a Q-Learning greedy agent. You can train it via:
python3 flappy_ql.py train greedy
This will generate a
model_greedy.txt file. You can run that via:
python3 flappy_ql.py run greedy
Does Flappy Tester Work?
Well, first, this is actually a really easy testing problem. You can see that by how relatively simplistic the code base is. Incidentally, ask yourself this: if you run your test tool (that I have encoded when you run ‘train’), how long will it take? How many test cases (episodes) will it need to generate? How long before it feels it has adequately learning anything about your interface?
You might doubt that I even have a working implementation. Fair enough. There is a
ref_models directory. In that are some pre-baked models that I ran. You can copy those files from that directory into the main project directory. Then run the above commands again with the
run parameter. See how the test tool plays against the interface.
TESTER! Notice something interesting there. I just gave you a way to run all this on your own but also gave you a way to short-circuit all that learning and training. As a tester,
that should interest you. That’s the case whether you want to test systems that are based on AI, you want to write a test tool based on AI, or you want to trust a test tool based on AI.
Upping the Complexity
Okay, let’s leave Flappy Bird and the Flappy Tester behind for now. Let’s think about purchasing a book on Amazon.
You search for the particular book. You find it. (Success criteria.) You decide you want to get a physical book, not an ebook. (Success criteria based on making some decision.) So you add the book to your cart. (Success criteria.) Then you proceed to checkout from the cart. (Success criteria.) Perhaps you decide to apply some of your gift card points to this. (Success criteria based on making some decision.) You enter in your information (or use your existing information) to submit a purchase. Amazon confirms that you made the purchase and probably sends an email as well.
We have bits of positive reward in there, just like with Flappy Bird, but really it’s at that last point that the overall reward is achieved. We succeeded in actually making a purchase and the reward signal was being told we did so. But it was a delayed reward, as you see. And it was a reward that was the case regardless of certain decisions made but very specific to certain other decisions made. And even then, of course, true reward (from a user perspective) doesn’t come until an actual book is delivered. Which is not something we would likely be testing fully, unless it was an ebook.
We have bits of correctness and we have contextual value.
So reinforcement learning is learning what to do, given a situation and a set of possible actions to choose from, in order to maximize a reward. (“I want that book and I want it for as cheap as possible; but I guess I’m okay waiting a few days for it; although I don’t want to wait too long. I might be willing to use some of my points since it’s kind of an expensive book but only if I have enough points for a few other things I might want.”) There’s a lot of balances here.
The learner — call it the agent — is not told
what to do. Rather, the agent must discover this through interacting with an environment. The goal for the agent is to choose its actions in such a way that the cumulative reward is maximized. So choosing the best reward now (“1-day shipping!”, “Use all my points to get it for free!”) might not be the best decision in the long run. But all of these are valid test scenarios.
So the trick is figuring out how to order the book and make decisions along the way. Each such path could be considered a test scenario or test case. And this is presumably what many testers want AI to do for them: not just executing the tests, but learning the application such that it can build those tests.
Well, an AI agent has to train to figure out those things, just as a human would have to train.
So, in this context, it’s not that you, as a tester, couldn’t think of creating those test cases; it’s whether an AI can. After all, why would it? What would be its activation function (for a neural network) or its utility function (for reinforcement learning) that encourages it to do so? What would be its reward system (both positive and negative)? And if you say: “Well, I would program it to have those things” — then it’s not really intelligence, per se, because it’s not doing these goal-setting exercises on its own.
Framing These Discussions
What I’ve mainly showed you here is what’s called ANI — Artificial Narrow Intelligence. What would be needed to truly model testing in a tool is an implementation of AGI — Artificial General Intelligence. This would require goal-setting which in turn would require intention. That would require an agent that generalizes what it has learned; it would require that this agent understands meaning and context.
After all, how would the agent recognize what a bug is? If it sees a 404 or 500 error page? If an application error window pops up? Well, we can do that now without AI. If the application doesn’t respond in a certain time frame? Well, again, we can do that now. Check if someone who lacks credentials can access something they should not be able to? You guessed it: we can do that now.
In order to do with AI automation what we can’t do now with non-AI automation, a testing tool based on AGI would have to be able to synthesize new knowledge, have intentionality, and understand what it means to have agency. For example, try to ask my test tool agent this: is Flappy Bird fun? Which might come down to asking it this: how hard is Flappy Bird? Is it too hard to be fun? What might help keep it difficult enough but not to the point of inducing rage?
Again, in a Flappy Bird context, this actually isn’t too hard. In the context of that Amazon example, it can be a little trickier.
What makes general human intelligence — and thus any artificial aspect of it as well — is the scope of the goals that we set for ourselves. That scope, and those goals, will be constrained by some environment, which will dictate the types of actions we can take, and the type of observations we can get. Those will all speak to test conditions and data conditions.
For ANI, we’re simply talking about human augmentation. And it’s arguable that our current automation tools do this plenty well. They don’t do the AGI — the test design or test creation for us. Could they? Should they? The idea of a test supporting tool moving from the ANI to the AGI means forming intent, the ability to understand and set up goals, and the ability to frame the intent as part of the goals.
Wrapping Up
This post had a few points to make.
- It’s really easy to write a “learning” testing tool. I just did that here with the ‘train’ aspect of the code. It’s literally generating test cases of all the possible ways of using the interface.
- It’s fairly easy to build learning algorithms into your test tool. Here I use Q-Learning and a Deep Q Network to provide a neural network.
- It’s really easy to lose sight of the parameters that have to be tested. I asked you above to figure that out. And it should have been really easy: it’s right there in the code.
- It’s really easy to lose sight of how well your testing tool is doing.
This was about the use of artificial intelligence (AI), not just machine learning (ML). There are many aspects of machine learning that can be very helpful for AI. But people are often talking about AI. Artificial Intelligence is the overarching science that is concerned with intelligent algorithms, whether or not they learn from data. In contrast, Machine Learning is a subfield of AI devoted to algorithms that learn from data.
AI doesn’t really bring us intelligence; it brings us a component of intelligence, which is prediction. AI is a prediction technology. Predictions are inputs to decision making. Uncertainly is why prediction is necessary; if we knew exactly what would happen, then there would be no uncertainty. Better prediction reduces uncertainty. So how does AI change the predictions you rely on? How much will AI save you on the cost of prediction? Most of this is really asking questions of the form: “What would a human do?” “What would a human recognize as a problem?”
All of the material for this post was really easy to create (that should give hope) but it also shows many of the limitations that have to be overcome (that should give caution). Thus I hope I’ve acted not like the current tool vendors but also not like the professional consultants.
I’ll close with a quote from the book
The Master Algorithm:
“Teach the learners, and they will serve you; but first you need to understand them. What in my job can be done by a learning algorithm, what can’t, and—most important—how can I take advantage of machine learning to do it better? The future belongs to those who understand at a very deep level how to combine their unique expertise with what algorithms do best.”
