In this post, I’m going to continue discussing the memory that I began pulling information from in the previous post. Here the focus will be a bit more on the structure of the memory.
I titled this post “Basics of Grue Memory” but, really, what this post is about is how the Z-Machine itself utilized memory. That will then let me see what Grue, acting as a Z-Machine emulator and interpreter, has to consider about memory.
A Virtual View of Memory
The Z-Machine specification, referring to zcode programs back in the late 1970s and early 1980s, says this:
They were still perhaps 100K long, too large for the memory of the home computers of their day, and the Z-machine seems to have made the first usage of virtual memory on a microcomputer.
That “first usage” bit is wrong. In fact, the concept of virtual memory was known at that time and did have some practical implementations. Virtual memory first saw use in an early supercomputer developed at the University of Manchester called the Atlas, officially commissioned in 1962.
It’s also worth noting that even in 1979, when the Z-Machine first came to be, the idea of a virtual machine was not unheard of. There are two relevant bits of history here.
- Between 1965 and 1967, a team at IBM had worked in close partnership with MIT’s Lincoln Laboratory to create an operating system called CP-40. This operating system simulated the operations of an IBM mainframe entirely in software. CP-40 eventually became the basis of the appropriately named VM operating system, which was first released by IBM in 1972.
- In 1978, a Pascal implementation known as UCSD Pascal introduced something called the P-Machine. This was a portable virtual machine that allowed programs written in UCSD Pascal to run on many different microcomputers, including even the Apple II following the release of Apple Pascal in August of 1979.
Fun fact: it was that idea of the P-Machine that became a major influence on Infocom’s own virtual Z-Machine.
In a virtual memory system, each program doesn’t interact directly with the computer’s physical memory. Instead, it operates within an idealized memory map — a virtual address space — which may have little resemblance to the actual layout of physical memory. When the program reads from or writes to this virtual map, the system is responsible for translating these virtual addresses into real physical addresses in memory, allowing programs to work as though they have access to a much larger memory space than physically available.

Great, but what does this all actually mean?
The Z-Machine specification says:
In the Z-machine, numbers are usually stored in 2 bytes (in the form most-significant-byte first, then least-significant) and hold any value in the range $0000 to $ffff (0 to 65535 decimal).
The specification uses a convention where a $ indicates hex values. In most computer languages, you’ll see those prefixed instead with 0x.
At any given time, the Z-Machine typically has a total addressable space of 64 kilobytes, which translates to 65,536 bytes. This limit represents the maximum memory the Z-Machine can address within its execution environment. In today’s terms, that seems pretty limited, right? But when you consider the 8-bit machines the Z-Machine was designed to run on — machines with constrained memory and processing power — it’s a clever solution. These limitations forced the design of the Z-Machine to make efficient use of memory, while still being portable across platforms. This being said, consider that the specification also says this:
The maximum permitted length of a story file depends on the Version, as follows:
Versions 1-3 128
Versions 4-5 256
Versions 6-8 512
The specification doesn’t specify units, but these values refer to kilobytes. So, how do these numbers reconcile with the Z-Machine’s 64-kilobyte addressable space limit?
A Paging View of Memory
The key is that the Z-Machine could manage multiple 64-kilobyte segments of memory. This was achieved using memory management techniques like paging or swapping, which allowed the interpreter to work with storage beyond the 64 kilobyte boundary.

In simple terms, the Z-Machine divided its memory into 64-kilobyte pages, which could be loaded into memory dynamically as needed. At any given time, the Z-Machine could address up to 64 kilobytes of memory, but the total memory footprint of a zcode program could be much larger. The interpreter would swap pages in and out of memory, enabling programs to run on systems with very limited physical memory.
For example, a zcode program could easily exceed the memory available on early 8-bit computers like the TRS-80, Commodore 64, or Apple II, but the clever use of paging allowed these larger files to run within the constraints of the hardware.
Does This Matter?
I’m going to describe how the Z-Machine handled memory, but it’s important to preface this by saying that most of these memory considerations are largely irrelevant if you’re running a Z-Machine implementation on modern hardware. However, some developers write implementations for older systems or emulators of those systems, where these details still matter.
As just a few examples, consider Ozmoo which provides an interpreter that can run on a Commodore 64. Another interesting example is zemu, a Z-Machine emulator for TI-84+ CE calculators. Or consider Z-MIM, a Z-Machine emulator written in MMBasic, for the Colour Maximite 2. Another interesting example is the A2Z Machine, which is an Arduino port. Yet another interesting example is Z3, which is a Z-Machine emulator written in Verilog, allowing it to run on a Field Programmable Gate Array (FPGA).
Memory Windows and Switching
To manage the memory constraints, the Z-Machine implemented a system of memory windows — smaller sections of memory that could be swapped in and out of the 64-kilobyte address space as needed. These windows typically held the program’s code, data, and stack, along with any other structures required during execution.
Infocom’s interpreters used a technique called bank switching to handle this. When the Z-Machine needed to access memory outside of the active window, it would switch to the appropriate bank. This involved temporarily storing the current memory window and loading a new one from either disk or a different part of memory, allowing the program to continue execution seamlessly.
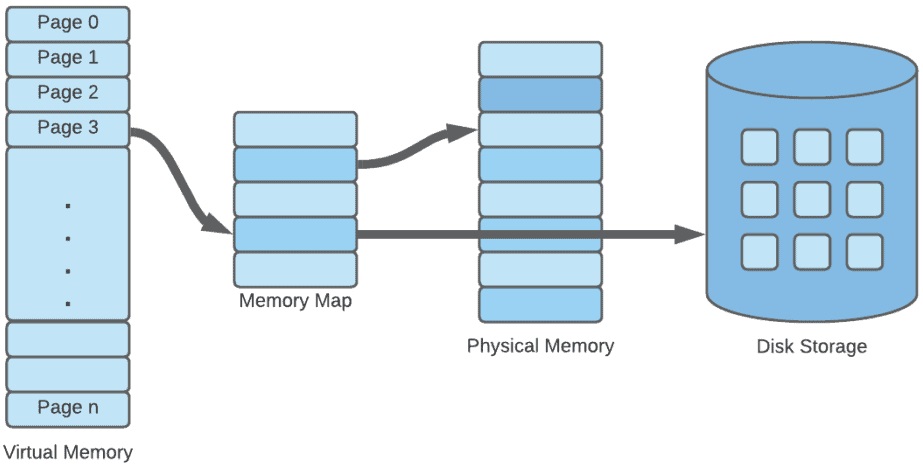
This approach allowed the Z-Machine to work within its 64 kilobyte address limit while effectively accessing a larger pool of memory.
Addressing the Memory
With memory available, it was essential to be able to access it. In the Z-Machine, a 16-bit pointer was used to address memory locations within the program’s virtual memory space. This allowed the Z-Machine to reference up to 65,536 memory locations, corresponding to its 64-kilobyte address space.
To contrast, modern systems like the Java Virtual Machine (JVM) use 32-bit or 64-bit address spaces, depending on the system architecture and JVM implementation. This means that in Java, pointer sizes can be 32 or 64 bits, allowing much larger amounts of memory to be addressed. The specific pointer size directly affects the maximum addressable memory available to the JVM.
However, in the late 1970s and early 1980s, home computers typically used 8-bit processors, making 16-bit addressing the norm. Systems like the Commodore 64, ZX Spectrum, and Apple II had 16-bit pointers, enabling them to address up to 64 kilobytes of memory. As technology advanced in the mid-1980s, we saw the rise of 16-bit systems, such as the IBM PC/AT with its Intel 80286 processor and the Commodore Amiga, which also used 16-bit addressing.
However, based on the discussion above, you might notice a limitation: the Z-Machine’s memory state can be larger than what a 16-bit pointer can address. Since a 16-bit pointer can only access 64 kilobytes of memory, how did the Z-Machine handle larger programs?
The solution was to use a segmented memory model, where memory was divided into smaller chunks called pages. Each page had its own addressable range, and the interpreter used a separate pointer to index into the current page. This allowed the Z-Machine to work with much larger memory spaces, even though the pointer was limited to 16 bits.
Here’s a visual representation to illustrate this concept:
+----------------------------------+
| Memory Page 1 |
+----------------------------------+
| 16-bit Pointer (0x0000 - 0xFFFF) |
| |
| Addressable Range |
| 0x0000 - 0xFFFF (64K Bytes) |
+----------------------------------+
+----------------------------------+
| Memory Page 2 |
+----------------------------------+
| 16-bit Pointer (0x0000 - 0xFFFF) |
| |
| Addressable Range |
| 0x0000 - 0xFFFF (64K Bytes) |
+----------------------------------+
In the above schematic, each memory page represents a separate region of memory with its own addressable range. The 16-bit pointer can access the entire addressable range within each page, covering the range from 0x0000 to 0xFFFF (64 kilobytes).
When a zcode program required more memory than a single page could provide, additional pages would be allocated. The interpreter would use memory banking or paging techniques to switch between these pages, allowing the program to access different regions of memory.
This is a lot of technical detail and the various visuals combined with description in this post is some insight into what helped me conceptualize how the Z-Machine handled memory larger than 64 kilobytes and allowed me to reconcile what I was reading in the Z-Machine specification. What this did was set me up for understanding “regions” of memory that the specification talks about and in the next post I’ll dig into those.
