In the previous posts we looked at setting up a graph pipeline and auditing that pipeline. All of this was based on an ontology, but one that was minimally constructed. Let’s dig more into ontologies here, specifically in relation to an actual specification for some actual software.
![]()
In this post, we’re going to hand-craft an ontology from a formal technical specification, generate a structured text rendering of that specification, with the eventual goal (in the next post) to use both artifacts to prompt a local model into producing a working code implementation.
Real World Applicability
This is not purely an academic exercise. In a real working context, a team might hand-craft an ontology and knowledge graph to capture the structure of a system (its components, their relationships, and the rules that govern them), and then use that formal representation as a specification for code generation via an AI model. The ontology becomes a precision instrument: instead of prompting a model with prose and hoping it infers the right structure, you give it structure directly and ask it to translate that structure into working software.
There’s a deeper principle at work here. When we hand-craft the ontology ourselves, we are creating a human-authored source of truth: a document that encodes what we know, what we’ve decided, and what the rules are. When we then ask a model to generate code from that source of truth, we have something we didn’t have before: a basis for accountability. We can ask not just “does the code work?” but “does the code faithfully reflect what the ontology says?” That is a meaningful question precisely because the ontology is ours. We wrote it. We can read it. We can point to a specific triple and say: the model honored this constraint, or it did not.
This is the foundation of explainable and interpretable AI. Not a black box that produces output we have to take on faith, but a pipeline where every decision traces back to a human-authored artifact that we understand and control. Trustable AI, in other words, is not primarily a property of the model; it’s a property of the pipeline the model operates within.
Which Specification?
This post needs to pick a specification and, ideally, one that anyone can get their hands on. It also has to be a specification that is substantive enough to show some ideas but (relatively) trivial enough to cover in a blog post. For that reason, I’ve chosen the Z-Machine specification. Let me give you some context for this.
The Z-Machine: A Brief Orientation

In the late 1970s, a company called Infocom had a problem that will sound familiar to anyone who has worked in software: they wanted to ship a product on multiple platforms without maintaining a separate codebase for each one. Their product was interactive fiction: text-based story games where the player types commands and the story responds, better known as “text adventures.” The platforms were the Apple II, the TRS-80, the VIC-20 and Commodore 64 machines, and whatever came next.
Infocom’s solution was a virtual machine. Rather than writing each game directly for each platform, they wrote their games to target an imaginary computer, the Z-Machine, and then wrote a small interpreter for each real platform that could run any Z-Machine program. Port the interpreter once per platform, and every game runs everywhere. The “Z” stood for Zork, their flagship title and the game that largely put interactive fiction on the map.
This architecture held up well enough that it survived Infocom’s acquisition by Activision in 1986 and the eventual discontinuation of commercial interactive fiction as a genre. In 1993, Graham Nelson wrote Inform, a programming language that compiled to the same Z-Machine format, making it possible for independent authors to write and distribute interactive fiction using the same virtual machine Infocom had designed fifteen years earlier. At that time, the Z-Machine specification was formalized and eventually published as a community standard.
When I refer to Infocom in this post, I mean the original company and the story files (called zcode programs) they shipped between roughly 1979 and 1989. When I refer to Inform, I mean Graham Nelson’s compiler and the community of authors who have used it since the 1990s.
The original specification can be found as The Z-Machine Standards Document Version 1.1. There is also a Version 1.1 (annotated) edition of the specification as well.
Today the Z-Machine is something of a living fossil: technically obsolete, but still actively used, (somewhat) carefully documented, and interpreted by multiple modern implementations. For my purposes it has one property that makes it an ideal domain for this series: its specification is (largely) precise, finite, and publicly available. There’s a ground truth to measure against.
A common practice is to use the Z-Machine as a project to build an emulator/interpreter. In this, it’s about as popular, perhaps, as the CHIP-8 interpreter, which is also used by a lot of people who want to try their hand at retrogaming engineering.
Our (Hypothetical) Project
So, let’s say you work at a company that is going to be producing a Z-Machine interpreter for modern audiences so that people can enjoy the text adventures of an early gaming era. A large part of this work will be done by having AI do the work. By which I mean, code generation.
AI generating the code is not the same thing as AI generating good code. This means there is a need to test whatever the AI generates. This is no different, in principle, for the need to test whatever a human developer generates. But, as a tester working in an AI-enabled context, we are suggesting the use of ontologies and knowledge graphs to keep the AI as trustable as possible.
Just like the developers, we, as testers, should take some time to understand the specification and what it is, exactly, that we are all going to be producing and delivering to customers.
While reading the specification, one thing worth thinking about early is something fairly obvious: the Z-Machine has a natural seam between the memory model (how data is laid out) and the execution model (how opcodes behave). From a testing standpoint, that’s relevant because those two subsystems have different ontological characters: the memory model is mostly taxonomic (what things are), while the execution model is mostly relational and procedural (what things do to each other).
I bring this up because focusing on the entire spec might be a bit challenging for this post. However, there are sections of the functionality that we could consider. A good example is suggested in the overview.
the header, at the bottom of memory, giving details about the program and a map of the rest of memory;
The memory map section also says this:
By tradition, the first 64 bytes are known as the "header".
Both Infocom and Inform produced Z-Machine story files, and both left traces in the header format (some normative, some merely conventional) that our AI code generator will need to model.
A key thing to understand about the Z-Machine is a statement made in the Preface:
Eight Versions of the Z-machine exist, and the first byte of any "story file" (that is: any Z-machine program) gives the Version number it must be interpreted under.
This idea of “versions” ends up being quite important. From a tester standpoint, what you are probably (hopefully!) thinking about here is that each version of a zcode program would be a particular data condition. Further, you might wonder if there are equivalence classes in these eight versions.
What all of this suggests is that the header is ideal as an entry point for several reasons that reinforce each other.
- It’s complete and bounded. The header is exactly 64 bytes. Further, when reading the spec, it’s clear that every field has a defined offset, type, and meaning, and that the relationships between fields are explicit. There’s no ambiguity about what “done” looks like. You can load a real zcode file and, as one example, either read the version number correctly or not.
- It’s a microcosm of the whole spec. The header contains examples of nearly every ontological challenge you will generally face: typed fields, bitfields (flags), fields whose interpretation depends on other fields (version-conditional behavior), and cross-references to other parts of the spec. If the ontology can express the header cleanly, you would have a template for everything that follows.
- The testing story is unusually clean. Real zcode files are freely available: the Infocom back catalog, modern Inform games, various standard test files. You can, for example, run the generated implementation against Zork and get a binary pass/fail on every field. That’s a satisfying demonstration for a testing audience reading this article because the ground truth is unambiguous.
Reading the Spec: The Header Table
Looking at the spec, for details about the header in particular, the relevant sections are the following:
The idea here is that before a Z-Machine interpreter executes a single opcode, it reads the header to learn what it’s dealing with: which version of the Z-Machine the story targets, where the dictionary and object table live in memory, what capabilities the game wants from the interpreter, and what the interpreter is required to report back.
Section 11 of the spec presents this information as a table. Here’s a representative excerpt:
Hex V Dyn Int Rst Contents
0x00 1 Version number (1 to 6)
0x01 3 Flags 1 (in Versions 1 to 3):
* * Bit 1: Status line type: 0=score/turns, 1=hours:mins
* * Bit 4: Status line not available?
4 Flags 1 (from Version 4):
* * * Bit 0: Colours available? [V5+]
0x04 1 Base of high memory (byte address)
0x06 1 Initial value of program counter (byte address)
6 Packed address of initial "main" routine
0x26 5 * * Font width in units
6 * * Font height in units
0x27 5 * * Font height in units
6 * * Font width in units
0x36 5 Header extension table address (bytes)
Five columns are situated with the contents of each field. Understanding what they express is the key to understanding the ontology we’ll build from them.
- Hex is the byte offset: the address within the header where this field lives. Offset 0x00 is the first byte, offset 0x36 is byte 54. These are fixed positions that an interpreter reads directly.
- V is the earliest version in which this field exists. A field marked V1 has been present since the beginning. A field marked V5 didn’t exist in earlier story files and an interpreter must not assume it’s present when reading a Version 3 file.
Then we come to the three access authority columns. An asterisk means “yes,” a blank means “no.”
- Dyn means the game (the running story file) may legally change this field during play.
- Int means the interpreter (the program running the story file) may legally change this field during play.
- Rst means the interpreter must set this field correctly after loading, after a restore operation (from a saved game state), and after a restart.
Fields with no asterisk in any column are read-only. Neither the game nor the interpreter should alter them after the story file is loaded. The version number at offset 0x00 is the clearest example: it’s written once by the compiler and never touched again.
The Contents column describes what each field means. For most fields this is a simple description. For flags registers (fields whose value is a collection of individual bits), the contents cell names the register and the rows beneath it describe each bit.
Three patterns in the table deserve special attention because they each require something beyond what a flat list of fields can express.
The first is version-gated bits. Look at the Flags 1 register. The same byte at offset 0x01 has completely different bit definitions depending on whether the story file is version 1 through 3 or version 4 and later. The reason for this is apparently that the register was redesigned when version 4 introduced new interpreter capability flags. Some bit positions were reused with different meanings.
The second is the version-conditional field swap at offsets 0x26 and 0x27. Notice that the table lists two rows for each of those offsets, with different contents depending on whether V is 5 or 6. In version 5, offset 0x26 is font width and offset 0x27 is font height. In version 6 those meanings invert: 0x26 becomes font height and 0x27 becomes font width. This is not a case where one field has two interpretations: these are genuinely different fields that happen to share an address across a version boundary. A flat table can show this with a note, but it can’t express the relationship between the two definitions.
The third is the header extension table at offset 0x36. Unlike every other field in the header, this one does not contain a value; instead, it contains an address. Reading offset 0x36 gives you the location of a separate structure elsewhere in the file, a self-describing table of additional header words whose length you only know after you read its first word.
These three patterns (version-gated bits, version-conditional field swaps, and pointer fields) are exactly the cases that make this domain interesting as a test of what an extraction pipeline can recover. A model that reads Section 11 and produces a flat list of fields has missed the structure. A model that recovers ideas like “superseded by” links, “contains bit” hierarchies, and “pointer to” relationships has understood the spec at the level the ontology requires. We’ll be able to measure the difference precisely because we have a gold standard to compare against: the ontology that we’ll build.
Notice what we’ve done here. We’ve taken time to actually read the spec, or at least the portion of it we are concerned with. This is no different than what would happen in a real-world work environment.
Building the Ontology
For this post, I built an ontology based on the specification. That ontology is available in the repo. Here I will take you through how I constructed it.
As in the previous posts, you probably have your own project folder you’ve been using. You can copy the zmachine directory from this repo over to your own project, if you wish to play along.
This ontology is a Turtle file (with a .ttl extension) and that means it’s a text-based format used to store and exchange Resource Description Framework (RDF) data, as covered in previous posts.
Prefixes
Every Turtle file opens with prefix declarations. These are nothing more than abbreviations, a way of avoiding namespace collisions while keeping the syntax readable. Our ontology uses four standard prefixes and one of our own:
|
1 2 3 4 5 |
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . @prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> . @prefix owl: <http://www.w3.org/2002/07/owl#> . @prefix xsd: <http://www.w3.org/2001/XMLSchema#> . @prefix zm: <http://example.org/zmachine/> . |
The first four are W3C standards that define the foundational vocabulary this ontology depends on: RDF and RDFS for basic graph structure and class hierarchies, OWL for richer logical constraints, and XSD for scalar datatypes like integers and booleans. You’ll encounter them in virtually every ontology because without them, the triples mean nothing. The zm: prefix is ours. This is the namespace for everything specific to this domain. Every class, property, and individual we define lives under that URI.
Thus, instead of writing http://example.org/zmachine/HeaderField every time, we write zm:HeaderField.
As noted in the earlier post in this series, the example.org domain is reserved by IANA specifically for illustrative use, which makes it exactly right here. Nothing resolves at that URL. If you were deploying this in production you would substitute your own domain.
The Ontology Declaration
Immediately after the prefixes, the file declares itself as an ontology:
|
1 2 3 4 5 6 7 |
<http://example.org/zmachine/> a owl:Ontology ; rdfs:label "Z-Machine Header Ontology" ; rdfs:comment """Gold standard ontology for the Z-Machine header, derived from Section 11 (normative) and Appendix B (conventional) of the Z-Machine Standards Document v1.1. Models header fields, bitfields, flags registers, the header extension table, version applicability, and access authority semantics (Dyn/Int/Rst).""" . |
The a owl:Ontology triple is the file identifying what it is. The rdfs:label and rdfs:comment are human-readable metadata. Nothing here affects inference or reasoning. This block exists purely for documentation and tooling. If you were to load this file into an ontology editor (more on those in a bit), this is what it reads to display the file’s name and description.
The comment already encodes a distinction worth flagging: normative versus conventional. Section 11 defines what a conforming interpreter must handle. Appendix B describes what Infocom and Inform compilers actually wrote in practice, some of which never made it into the formal spec. Both are in this ontology, and every individual is tagged with which category it belongs to. That distinction will matter when we evaluate what the extraction pipeline recovers. Missing a normative field is a more serious failure than missing a conventional one.
Class: HeaderField
Classes are the nouns of the ontology; the categories of things that exist in this domain. Here is one of the nine classes we define:
|
1 2 3 4 |
zm:HeaderField a owl:Class ; rdfs:label "Header Field" ; rdfs:comment """A field at a fixed byte offset within the Z-Machine header. Carries an offset, size, type, version applicability, and access authority constraints.""" . |
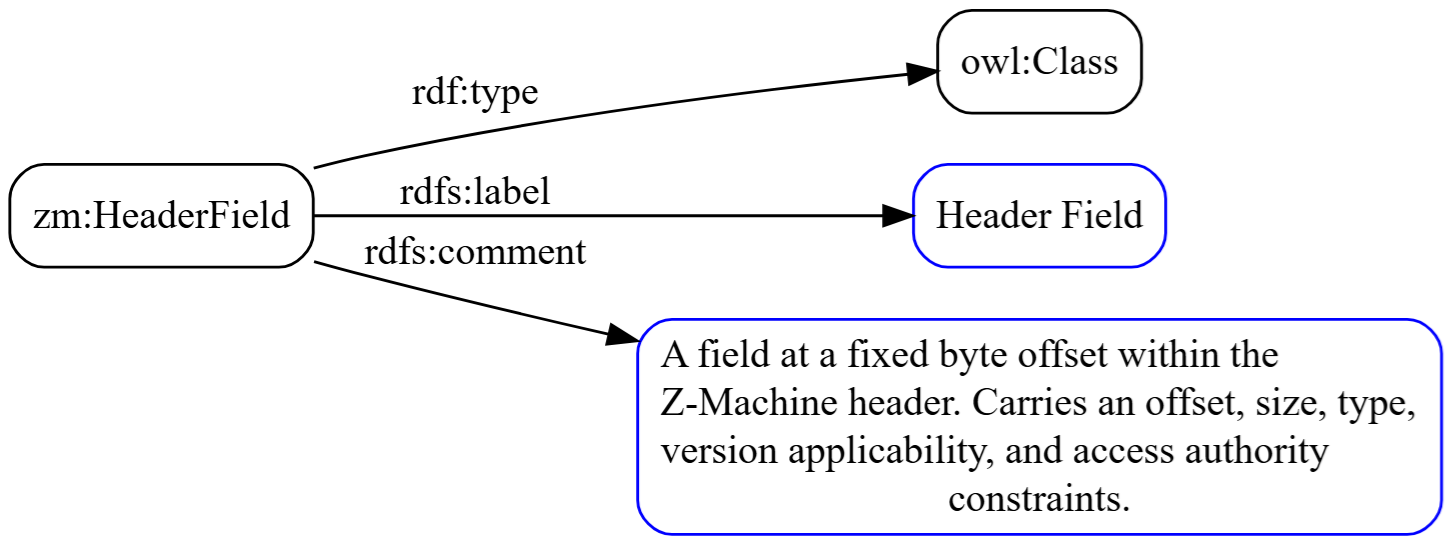
This says: zm:HeaderField is a class, it has a human-readable label, and it has a description. The class itself carries no data; it’s a category. The data lives on the individuals that belong to this class, which we’ll see shortly.
I won’t show every class declaration here, but two are worth noting in relation to HeaderField. The first is zm:FlagsRegister, which is declared as a subclass of zm:HeaderField.
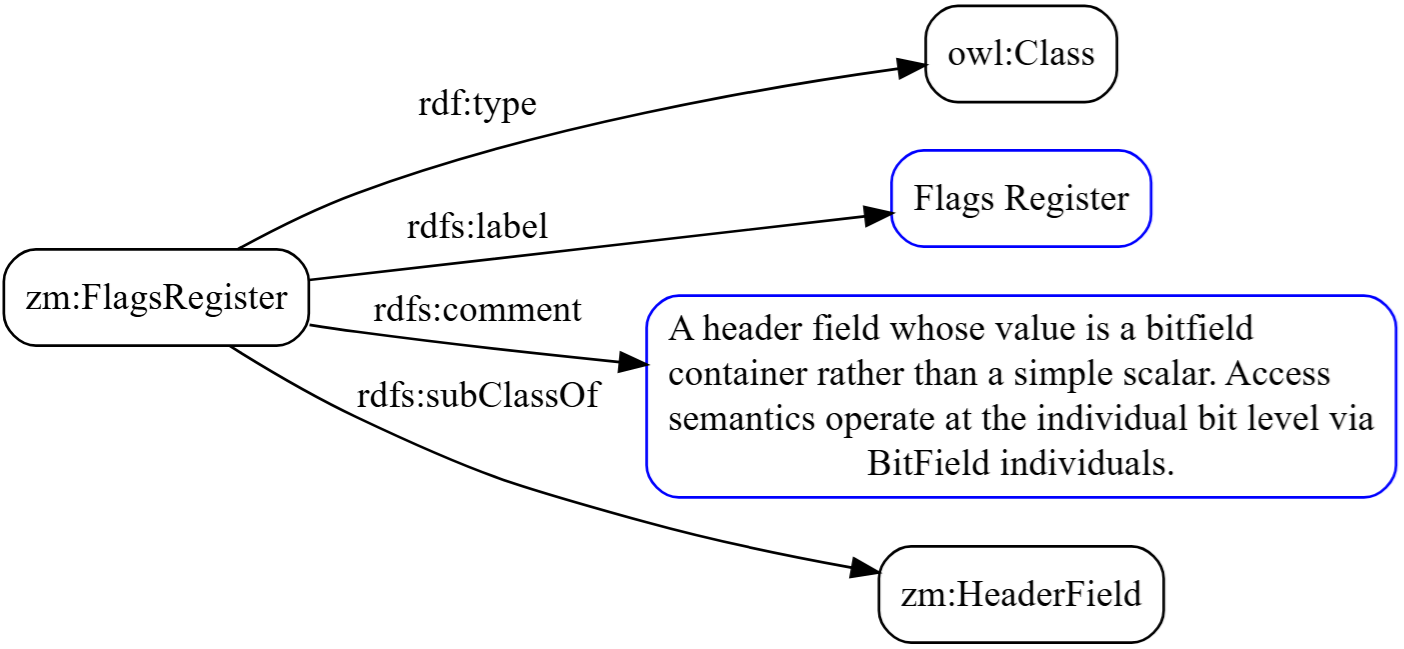
It is a header field, but one whose value is a container of bits rather than a scalar. Because it’s declared as a subclass rather than a peer class, FlagsRegister individuals automatically inherit all of HeaderField’s properties (offset, size, version applicability) without those needing to be redeclared. The subclass relationship is doing real work, not just organizing things tidily.
Another is zm:BitField, which is a separate class entirely, representing the individual bits within a flags register.
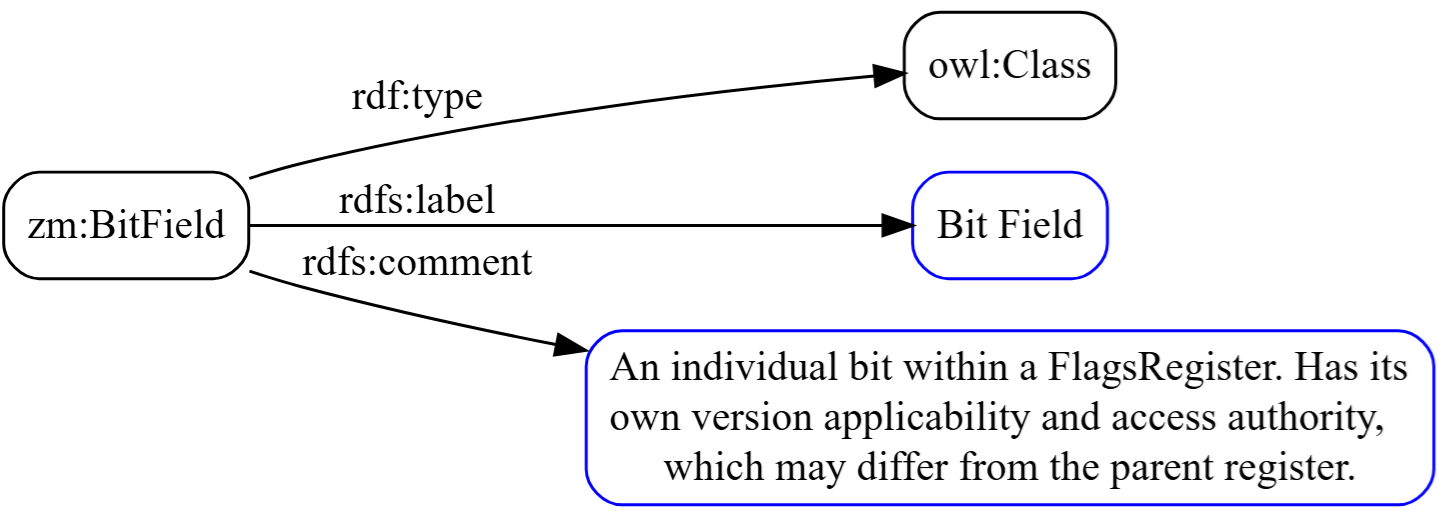
That three-level structure (register containing bits, both being distinct from plain fields) is the ontology doing work that a flat table simply can’t do.
Named Individual: zm:v3
Named individuals are specific instances of a class. The Z-Machine has six versions, and rather than representing them as plain literals we model each as a first-class entity:
|
1 2 3 |
zm:v3 a zm:ZMachineVersion ; rdfs:label "Version 3" ; zm:versionNumber 3 . |
This is zm:v3, an individual of class zm:ZMachineVersion, with a label and a numeric identifier.
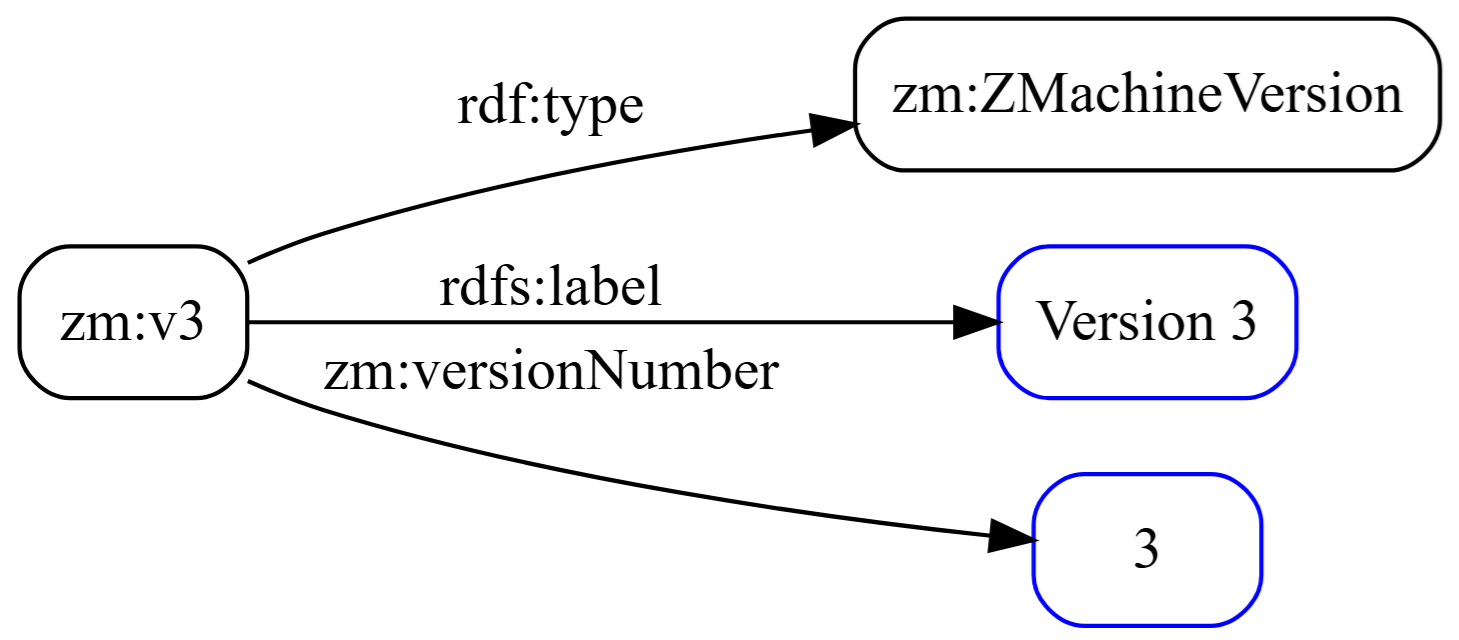
All six versions (zm:v1 through zm:v6) follow this same pattern.
Making versions into named individuals rather than plain literals is a deliberate design choice. When a field declares zm:applicableFrom zm:v3, it’s pointing to a node in the graph, not storing the string “3”. That means you can traverse the relationship, ask which fields share the same applicability, and reason about version ranges.
A literal value sitting in a column can’t participate in graph traversal, whereas a named individual can. That means a query can ask: “give me all fields where applicableFrom is v3 or later.” This is a question that requires the version individuals to be ordered and comparable, not just labeled.
Datatype Property: zm:offset
Properties are the verbs of the ontology; they describe relationships between things. Datatype properties specifically relate an individual to a literal value like a number or a string:
|
1 2 3 4 5 |
zm:offset a owl:DatatypeProperty ; rdfs:label "offset" ; rdfs:comment "Byte offset of the field within the header, as an integer." ; rdfs:domain zm:HeaderField ; rdfs:range xsd:integer . |
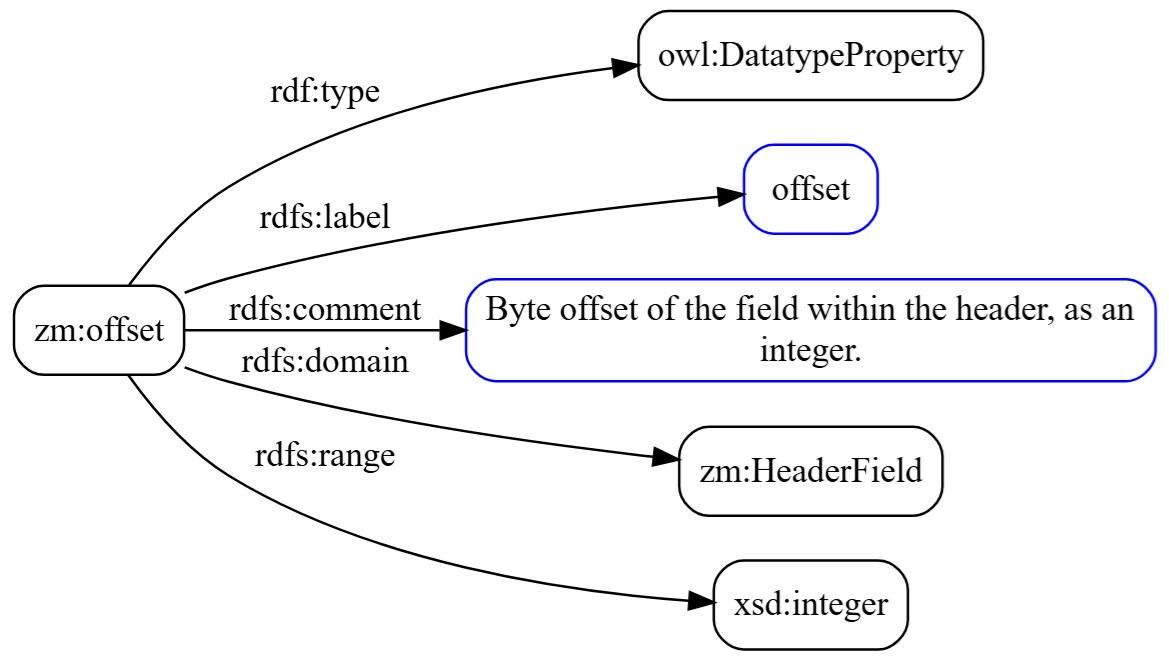
The rdfs:domain says this property applies to HeaderField individuals. The rdfs:range says the value is an integer. When you later see zm:offset 0 on a field individual, you’re reading a triple that says “this field’s offset is the integer 0.”
One thing worth noting for readers coming from a relational database background: domain and range declarations in OWL are not hard constraints that enforce correctness. They are inference hints. A reasoner seeing zm:offset applied to something will conclude that thing must be a HeaderField, rather than rejecting the triple as invalid. The ontology is descriptive, not a schema enforcing rules at write time.
Datatype properties are for facts that are intrinsic to a thing: its offset, its size in bytes, whether it must be reset on restore. They’re the leaves of the graph, terminal values rather than pointers to other nodes. The complement, object properties, handle those pointer relationships, and we’ll see them next.
Object Property: zm:applicableFrom
Object properties are the other kind of property, the kind that creates edges between nodes rather than edges to literal values. Instead of pointing to a literal value, they point to another node:
|
1 2 3 4 |
zm:applicableFrom a owl:ObjectProperty ; rdfs:label "applicable from" ; rdfs:comment "The earliest Z-Machine version in which this field or bit is defined." ; rdfs:range zm:ZMachineVersion . |
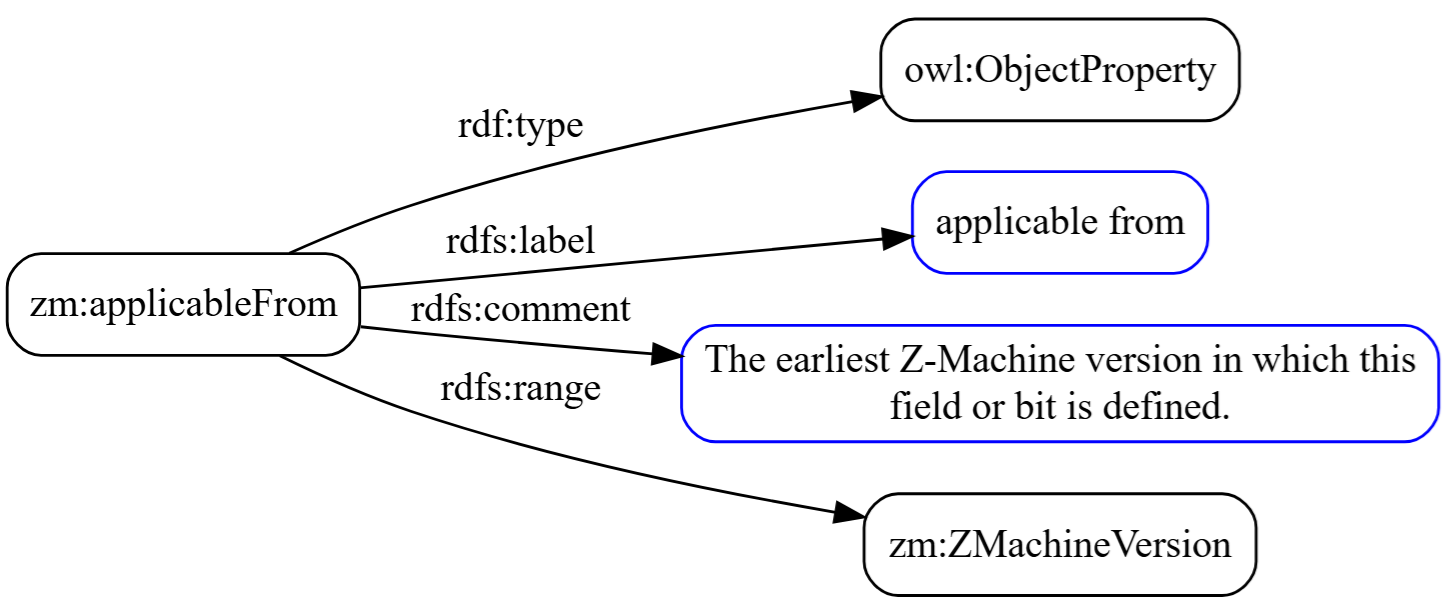
The rdfs:range here is zm:ZMachineVersion, which is a class, not a datatype. When a field declares zm:applicableFrom zm:v3, it’s creating an edge in the graph that connects this field to the zm:v3 individual we just saw. That edge is traversable. A SPARQL query can ask “give me all fields applicable from Version 3 or later” and follow those edges to find the answer.
Notice that this property has no rdfs:domain declaration, unlike zm:offset which had both. That’s deliberate: both HeaderField and BitField individuals use zm:applicableFrom, and constraining the domain to one class would require a union type or a workaround. Leaving it unconstrained is the cleaner modeling choice.
Incidentally, this is the structural difference between a spreadsheet and a graph. In a spreadsheet, the version column holds the value 3. In a graph, the field node and the version node are connected, and that connection is itself a queryable fact.
Complete Field: zm:field_version
Now we can read a complete header field individual and understand every line:
|
1 2 3 4 5 6 7 8 9 |
zm:field_version a zm:HeaderField ; rdfs:label "Version Number" ; zm:offset 0 ; zm:byteSize 1 ; zm:hasFieldType zm:byteValue ; zm:applicableFrom zm:v1 ; zm:hasSourceAuthority zm:normative ; zm:description "Z-Machine version number (1 to 6). Must be read before interpreting any other header field." . |
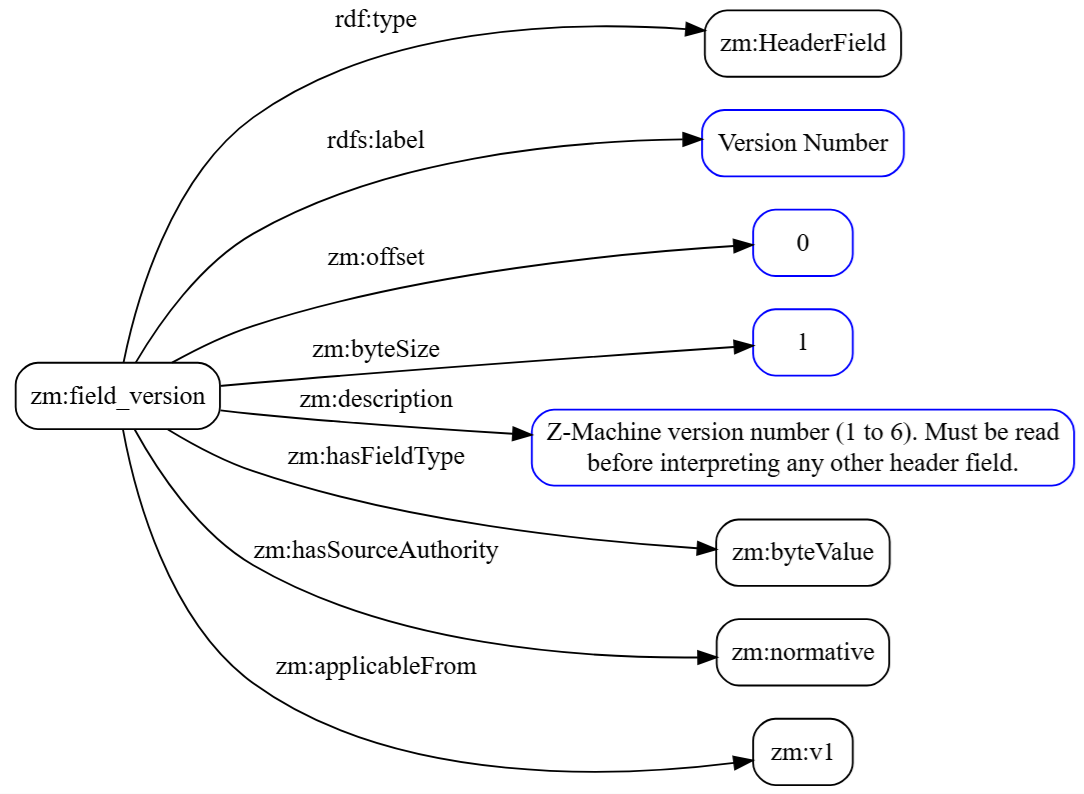
Reading this top to bottom: zm:field_version is an individual of class zm:HeaderField. Its label is “Version Number”. It sits at byte offset 0. It’s one byte in size. Its value is a plain scalar: not an address, not a packed address, just a raw number. It has been defined since Version 1. It’s normatively defined, meaning a conforming interpreter must handle it. And the description captures the most important implementation note: this is the first byte you read, because every other field’s interpretation may depend on what you find here.
Before reading the absences, one OWL convention worth knowing: an absent property means “not stated” rather than “false” or “inapplicable.” The ontology operates under the open-world assumption: silence is not denial. With that in mind, no access authority is set, which by our modeling convention means the field is read-only for both game and interpreter. No applicableUntil is set, which means it remains valid through Version 6. No supersededBy is set, which means its meaning never changes across versions. For the single most important byte in the entire header, this is reassuringly simple.
Where the Ontology Earns Its Keep
The version number field is deliberately uncomplicated. To see what the ontology can express that a flat representation can’t, consider what happens at byte offsets 0x26 and 0x27 in Versions 5 and 6:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
zm:field_font_width_v5 a zm:HeaderField ; rdfs:label "Font Width in units (V5, offset 0x26)" ; zm:offset 38 ; zm:applicableFrom zm:v5 ; zm:applicableUntil zm:v5 ; zm:supersededBy zm:field_font_height_v6_at26 ; zm:description "Font width in units. At offset 0x26 in Version 5 only." . zm:field_font_height_v6_at26 a zm:HeaderField ; rdfs:label "Font Height in units (V6, offset 0x26)" ; zm:offset 38 ; zm:applicableFrom zm:v6 ; zm:description "Font height in units. At offset 0x26 in Version 6 — swapped from the Version 5 meaning." . |
These two individuals share an offset in that both sit at byte 38. But they are not the same field. In Version 5, byte 38 is font width. In Version 6, the same byte is font height. The meanings have swapped. The same inversion happens at offset 39 in the opposite direction.
A flat table with a “version” column can’t express this. You would need either two rows with the same offset and a note in the contents column, or a single row with a compound description that a decoder has to parse. Either way, the version-conditional branching is implicit in the prose rather than explicit in the structure.
In the ontology, the branching is structural. zm:field_font_width_v5 has applicableUntil zm:v5, closing its validity window. zm:supersededBy links it explicitly to zm:field_font_height_v6_at26, which opens at zm:v6.
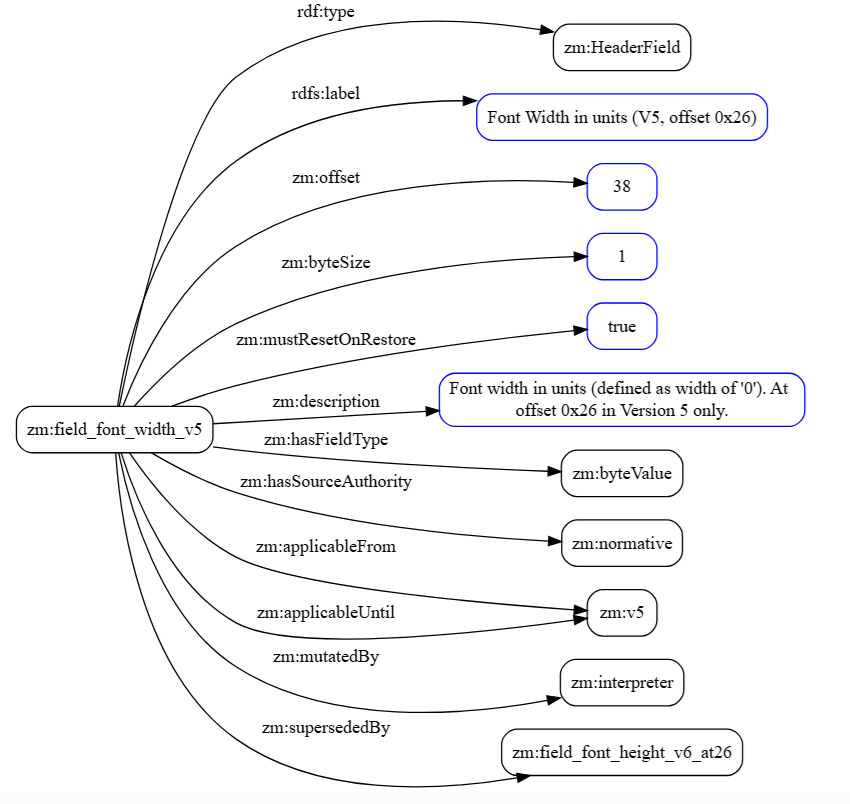
A decoder querying this graph (runtime querying) or an interpreter built from this graph (code generation from the ontology) can query for all fields at offset 38, find two results, check their version ranges, and select the correct one based on the version byte it read from offset 0. The spec’s intent is encoded in the graph rather than left in a comment.
This is the ontology earning its place in the pipeline. When we run extraction against Section 11 in the next stage, one of the most instructive findings will be whether the model recovers this version-conditional swap, or whether it produces a single field at offset 0x26 with a vague description, flattening the structure the spec is actually expressing. Either outcome is informative, and we can only measure it because we have a gold standard to compare against.
Building an Ontology
I just showed you my Turtle file rather than build it together for now. But a logical question is: how do you do this? The honest answer is: it depends on your starting point, and there’s a spectrum of approaches.
Build from Scratch
Turtle syntax itself isn’t that hard once you’ve read it for ten minutes. The prefix declarations, the subject-predicate-object structure, the semicolon shorthand for multiple predicates on the same subject. Those click quickly. What’s hard is the ontology design, not the syntax. Consider the decisions we worked through together: what counts as a class, how to model the Dyn/Int/Rst columns, how to handle the font field swap, and so on. Those require domain understanding and deliberate thought. No tool removes that cognitive work. They just change where you do it.
There are visual ontology editors. The most widely used tool is Protégé, which is free and maintained by Stanford. It gives you a GUI for defining classes, properties, and individuals, and it exports to Turtle, OWL/XML, or RDF/XML. For someone who finds raw Turtle intimidating it’s a reasonable starting point. The tradeoff is that Protégé’s interface can feel bureaucratic for what is essentially structured data entry, and the generated Turtle is often more verbose than hand-authored Turtle because it includes a lot of OWL machinery you may not need.
For our use case, a domain-specific ontology of modest size, Protégé would work but might feel like more tool than necessary.
Build from LLM
You can also do LLM-assisted authoring. This is actually where things get interesting for my post, because it’s directly relevant to the pipeline we’re building towards here. An LLM can produce a reasonable first-draft Turtle file from a clear conceptual description. You would prompt it with something like “here are my classes, here are my properties, here are the individuals” and it will generate syntactically correct Turtle that captures most of what you described. What it won’t do reliably is make the harder design decisions: the ones we had to reason through explicitly.
So, the practical workflow is usually this: work through the conceptual model in prose first (as we did), then prompt an LLM to generate the initial Turtle, then review and correct it. The LLM handles the syntax translation, you handle the design integrity. That’s a reasonable division of labor.
This might even be something you want to experiment with on your own.
Worth mentioning briefly: for common domains, ontologies already exist that you can import or extend rather than authoring from scratch. FOAF for people and organizations, Dublin Core for document metadata, OWL Time for temporal relationships. For the Z-Machine header there’s nothing pre-existing obviously applicable, but the principle matters: good ontology practice is to reuse existing vocabularies where they fit rather than reinventing them. Our ontology already does this implicitly by using RDF, RDFS, and OWL primitives rather than inventing its own type system.
Here’s how I would frame it for you: the Turtle file is the output of a design process, not the starting point. The design process is the hard part, and it’s inherently human in that it requires understanding the domain well enough to know what relationships matter and how to represent them faithfully. Once the design is clear, generating the Turtle is mechanical enough that an LLM or a tool like Protégé can do most of it. The skill to develop is the conceptual modeling, not the syntax.
Validate the Ontology
You’ve just seen how the ontology is structured; now let’s run a script and get concrete evidence that the structure is present and correct. Running validate.py against the ontology produces output in six sections. Let’s walk through what each one is telling us and why it matters.
Section 1: Parse
Triples: 771
The file parsed without errors and contains 771 RDF triples. This number will become a reference point later. When we run extraction and build a graph from what the model recovers, we’ll compare its triple count against this baseline. A significantly lower number is an early signal that the extraction missed structure. A significantly higher number is a signal that the model invented structure that isn’t in the spec.
Triple count alone is a blunt instrument. Two graphs can have the same number of triples while differing significantly in which ones they contain. But a large divergence in either direction is worth investigating before looking at anything else.
Section 2: Individual counts by class
This section provides a census of everything in the ontology, organized by type. Before looking at relationships or behavior, it’s worth confirming that the raw counts are what we expect — that the ontology contains the right number of the right kinds of things. Each number here is directly checkable against the spec.
owl:Class: 9
owl:DatatypeProperty: 7
owl:ObjectProperty: 9
owl:Ontology: 1
zm:AccessAuthority: 3
zm:BitField: 24
zm:ExtensionField: 7
zm:FieldType: 5
zm:FlagsRegister: 2
zm:HeaderExtensionTable: 1
zm:HeaderField: 35
zm:SourceAuthority: 2
zm:ZMachineVersion: 6
The counts are directly checkable against the spec. Six ZMachineVersion individuals because there are six versions. Two FlagsRegister individuals because there are two flags registers in the main header (Flags 1 and Flags 2). Five FieldType individuals because there are exactly five ways a field value can be typed: byte value, word value, byte address, packed address, and bit container. And so on.
The numbers that repay closer attention are the ones that aren’t immediately obvious from a casual reading of the spec. 35 HeaderField individuals, for instance, is higher than a naive count of the rows in Section 11’s table would suggest — because the font dimension swap at offsets 0x26 and 0x27 contributes four individuals where a flat reading sees two rows. 24 BitField individuals reflects the full version-stratified breakdown of Flags 1 and Flags 2, including bits that share a position but apply to different version ranges. These inflated counts are not errors. They are the ontology being precise where the spec is implicitly complex.
The counts for the infrastructure classes are also visible here: nine classes, seven datatype properties, nine object properties. Those numbers are stable; they reflect our ontology design decisions and shouldn’t change unless we revise the schema itself. If you run this script after editing the ontology and one of those numbers shifts unexpectedly, you’ve caught an unintended side effect before it propagates anywhere.
Section 3: Structural relationships
This section confirms that the relationships we modeled explicitly — the ones that go beyond a flat list of fields and their properties — are actually present in the graph and wired correctly. These are the structural connections that make the ontology more than a spreadsheet: version-conditional replacements, indirect addressing, and register-to-bit hierarchies. If any of these were missing or malformed, the validation output would show gaps here rather than the clean lists below.
--- supersededBy ---
zm:field_initial_pc_v1to5
-> zm:field_initial_pc_v6
zm:field_serial_v2
-> zm:field_serial_v3plus
zm:field_font_width_v5
-> zm:field_font_height_v6_at26
zm:field_font_height_v5
-> zm:field_font_width_v6_at27
--- pointerTo ---
zm:field_header_extension_ptr
-> zm:headerExtensionTable
--- containsBit (FlagsRegister -> BitField) ---
Flags 1: 13 bit(s)
Flags 2: 10 bit(s)
This section confirms that the three structural relationships we modeled explicitly — supersededBy, pointerTo, and containsBit — are present in the graph and wired correctly.
The four supersededBy links capture version-conditional field replacements: the initial program counter changes from a byte address to a packed address at Version 6, the serial code gains a defined format at Version 3, and the font dimension swap at offsets 0x26 and 0x27 contributes two links, one for each offset. These are not incidental connections. Each one encodes a decision point that a decoder must navigate correctly. If extraction misses a supersededBy link, the downstream code generator has no way to know that the meaning of a byte changes across a version boundary.
The single pointerTo link is equally load-bearing. Offset 0x36 does not contain a value; it contains an address. The pointerTo relationship makes that indirection explicit in the graph rather than leaving it implicit in the field’s description text. A generator that misses this link will treat the header extension table as a scalar field and produce code that reads a number where it should follow a pointer.
The containsBit counts — 13 bits in Flags 1, 10 in Flags 2 — confirm that the register hierarchies are intact. These numbers are higher than a flat reading of the spec might suggest, for the same reason the HeaderField count was: Flags 1 was redesigned at Version 4, and bits that share a position across that boundary are modeled as distinct individuals rather than collapsed into a single ambiguous entry.
Section 4: Access authority coverage
The key insight for framing this section is that access authority is where the ontology captures behavioral constraints, not just structural ones. The earlier sections were about what fields exist and how they relate. This section is about what agents are allowed to do during execution. That’s a different kind of information and worth naming as such.
The list is dominated by Interpreter entries, with only two Either entries (transcripting and screen redraw) and one Game entry (force fixed-pitch). That asymmetry is meaningful — it reflects the spec’s architecture where the interpreter reports capabilities and the game mostly reads them rather than setting them.
Notice this part:
Fields and bits with mustResetOnRestore = true: 33
Fields with no mutatedBy (read-only candidates): 26
The 33 individuals marked mustResetOnRestore represent a behavioral contract, not just a data layout. An interpreter that correctly reads these fields on initial load but fails to restore them after a save/restore cycle is non-conforming in a way that won’t show up in static analysis. Only a test that exercises the full load/save/restore cycle will catch it.
The 26 read-only candidates are equally important from a testing perspective. These are fields the spec says neither game nor interpreter should alter after the story file loads. A conforming implementation needs to treat them as immutable. That’s a constraint the ontology makes explicit and a test suite can enforce directly.
Section 5: Version applicability
This section surfaces the version applicability data as queryable facts. Every individual in the ontology carries an applicableFrom property, and some carry applicableUntil as well. “Applicable” here means the individual exists and carries its stated meaning for that version range. Outside that range, the individual simply does not apply — an interpreter should not consult it.
The first table counts how many individuals are first defined at each version:
zm:v1: 18 individual(s)
zm:v2: 2 individual(s)
zm:v3: 6 individual(s)
zm:v4: 8 individual(s)
zm:v5: 22 individual(s)
zm:v6: 12 individual(s)
Version 1 anchors 18 individuals because the core header structure was largely established from the beginning. Version 5 introduces 22 because that version significantly expanded interpreter capability reporting — colours, pictures, mouse, sound, UNDO, and the entire header extension table all arrive together at v5. Version 2 and Version 4 are quieter, each adding a small number of fields. The counts are not arbitrary; every individual traces back to a specific row or bit in the spec.
The second table shows individuals with a closed validity window — those carrying both applicableFrom and applicableUntil:
Font Height in units (V5, offset 0x27): zm:v5 to zm:v5
Font Width in units (V5, offset 0x26): zm:v5 to zm:v5
Initial Program Counter (V1-5): zm:v1 to zm:v5
Serial Code (V2): zm:v2 to zm:v2
These are the version-conditional cases where a field or bit exists for exactly the stated range and no other. The font dimension fields at offsets 0x26 and 0x27 each show zm:v5 to zm:v5 — a single-version window. They don’t disappear at Version 6; they are replaced by individuals with inverted meanings, connected via the supersededBy links we saw in Section 3. The Initial Program Counter runs zm:v1 to zm:v5, closing because Version 6 replaces it with a packed address. The Serial Code closes at zm:v2 because Version 3 redefines those same bytes as a compilation date in YYMMDD format. In each case the closed window is not an error — it’s the ontology being precise about where one meaning ends and another begins.
These properties don’t appear in the validation output by accident. Each one was declared explicitly in the ontology: applicableFrom and applicableUntil as object properties pointing to ZMachineVersion individuals, and supersededBy as an object property linking one HeaderField to its replacement. The validation script is simply querying for triples that use those properties and reporting what it finds. If the ontology had not modeled version applicability as first-class graph structure — if it had left version information in description strings instead — this section of the output would be empty, and the downstream pipeline would have no structured version data to work with.
Section 6: Bit position diagnostics
This final section runs two diagnostics against the bit-level structure of the ontology: a check for duplicate bit positions within a single register, and a census of source authority across all individuals.
Flags 1, bit 1: 2 individuals
[v1 to v3] Flags 1 bit 1: Status line type (V1-3)
[v6] Flags 1 bit 1: Picture displaying available (V6)
Flags 1, bit 5: 2 individuals
[v1 to v3] Flags 1 bit 5: Screen-splitting available (V1-3)
[v6] Flags 1 bit 5: Sound effects available (V6)
These look like errors but aren’t. Flags 1 bit 1 carries one meaning from v1 to v3 — status line type — and a completely different meaning from v6 onward — picture displaying availability. Nothing is defined at that position for v4 and v5. Bit 5 shows the same pattern: screen-splitting for v1 to v3, sound effects from v6. This is the Flags 1 register redesign at Version 4 made visible as data. The register was repurposed, and the ontology models each meaning as a distinct individual with its own validity window rather than collapsing them into a single ambiguous entry.
Flags 1 bit 0: Colours available (V5+)
register: Flags 1
applicableFrom: ['zm:v5'] applicableUntil: (open)
This individual appears in the “all BitField individuals at bit position 0” subsection, which the script runs as a spot-check. It shows applicableFrom set to zm:v5 and applicableUntil marked open — meaning this bit has been defined since Version 5 and remains valid through Version 6. Contrasting this with the duplicate entries above illustrates the difference between a bit that was redefined across a version boundary and one that was simply introduced at a particular version and never replaced.
Notice this in the output:
--- Duplicate bit positions within a single register (potential conflicts) ---
The label “potential conflicts” in the diagnostic header is deliberately cautious. The script cannot determine from structure alone whether two individuals at the same bit position are intentional version-gated redesigns or genuine modeling mistakes. It flags them and leaves the judgment to the reader. In this ontology every flagged duplicate is intentional, and the applicableFrom and applicableUntil values on each individual confirm that their validity windows never overlap.
zm:conventional: 7 individual(s)
zm:normative: 62 individual(s)
This final count connects back to the distinction introduced in the ontology declaration. Of the 69 individuals carrying a sourceAuthority triple, 62 are normative and 7 are conventional. Normative individuals trace to Section 11 of the spec — a conforming interpreter must handle them. The 7 conventional individuals trace to Appendix B, reflecting observed practice in Infocom and Inform files rather than formal requirements. When the extraction pipeline runs in the next post, failures against normative individuals are the ones that matter most. The ontology makes that distinction queryable rather than leaving it in a comment.
Convert the Spec
Before we can ask a model to extract triples from the Z-Machine spec, we need to give it something to extract from. The raw HTML of Section 11 and Appendix B is technically readable by a model, but it’s noisy — navigation elements, styling, repeated headers, and prose that surrounds the actual tabular data we care about. The convert.py script fetches both pages and transforms them into a structured plain text format that foregrounds the relational content: field offsets, version applicability, access authority columns, and parent-child relationships between registers and their bits.
This is not a trivial preprocessing step. The script makes explicit decisions about how to represent the table structure — how to express that a bit belongs to a register, how to handle version-conditional rows, how to distinguish normative from conventional fields. Those decisions shape what the model sees, and therefore what it can recover. Running convert.py produces two files, extraction_input_sect11.txt and extraction_input_appb.txt, which become the input to the extraction prompt in the next stage.
The goal is not to make the model’s job easy by pre-solving the extraction problem. The goal is to remove irrelevant noise while preserving the structural complexity that we want to measure. The ontology we just built is the gold standard. The extraction pipeline is about to tell us how much of that structure a model can recover on its own.
I recommend checking out the generated files and seeing how they compare to the spec sections.
Gathering Our Test Fixtures
Before we move to code generation, we need something to test against. The Z-Machine specification is only as useful as our ability to verify that an implementation actually conforms to it, and for that we need real story files.
The Infocom back catalog is freely available from the Obsessively Complete Infocom Catalog. For our purposes, three files cover the version range we care about:
- A Version 3 file such as Zork I gives us the earliest header format: the original flags register layout, score/turns status line, and no extended header.
- A Version 5 file such as Beyond Zork or any modern Inform-compiled game gives us the expanded capability flags, the header extension table, and the font dimension fields at offsets 0x26 and 0x27.
- A Version 6 file such as Zork Zero gives us the font dimension swap, the packed address for the main routine, and the full set of Version 6 interpreter flags.
Together these three files exercise every version-conditional branch in the header parser we’re about to generate. A parser that reads all three correctly, producing the right field values for each version, has demonstrated conformance against real artifacts, not just against the spec in the abstract. That’s the test that matters.
To save you some time, I’m going to provide some zcode files for you. They are available in the zcode directory, which is part of the zmachine directory.
- zork1-r88-s840726.z3 — Masterpieces version
- zork1-invclues-r52-s871125.z5 — Solid Gold version
- beyondzork-r57-s871221.z5 — Masterpieces version
- zork0-r393-s890714.z6 — Masterpieces version
The two z5 files are worth having both of. Zork I Solid Gold and Beyond Zork are different enough in their header profiles to be useful distinct test cases. Zork I Solid Gold gives you a game that existed in an earlier version and was recompiled, while Beyond Zork was written natively for v5 and makes fuller use of the capability flags.
The Masterpieces versions are a particularly good choice because they are well-documented releases with known serial numbers and checksums, which means we can verify we have the right files before running anything.
One small thing worth noting: the filename convention here is meaningful and worth a brief explanation. The format is title-rRELEASE-sSERIAL.zVERSION. So, zork1-r88-s840726.z3 is Zork I, release 88, serial number 840726, Version 3. Those release and serial numbers correspond directly to fields in the header, specifically offsets 0x02 and 0x12. That’s a satisfying detail for a testing audience: the filename is already telling you what to expect when you read the header.
Verifying Our Test Files
Before moving to the extraction stage, it’s worth doing one quick preparatory step with those files: verifying that each one actually reports the version you expect from its byte at offset 0x00. This sounds trivial but it matters for two reasons.
First, it establishes a known-good baseline. When your decoder later reads the version byte, you want to be able to say “we independently confirmed this file is Version X before we ran anything through the pipeline.” That’s good testing hygiene: ground truth should be established independently of the thing being tested.
Second, it surfaces any surprises early. Zcode files occasionally circulate with misleading filenames, and some Version 3 files have quirks like missing file length and checksum fields that the spec explicitly notes. Better to know that now than mid-pipeline.
The check itself is just reading a single byte, so it’s a one-liner per file.
|
1 2 3 4 5 6 |
import sys with open(sys.argv[1], "rb") as f: version = f.read(1)[0] print(f"Z-Machine version: {version}") |
You just pass whatever zcode file you want to this script as an argument. So if you called this script check.py, you could just do this:
python check.py zork1-r88-s840726.z3
This script reads offset 0x00 from each file and reports back the version, which, as I said, I already knew it would since I have known working files.
Next Steps!
This feels like a good place to stop for now as we have our setup ready to go. In the next post, we’ll create the prompt that we can feed to a model and have that model generate code for us, based on the ontology, that will (hopefully!) show how to create the beginnings of a Z-Machine interpreter.
