In the previous post we looked at the code for an entire pipeline that uses a lightweight ontology to guide extraction and construct a queryable knowledge graph from unstructured text. Here, we’ll look at auditing what this pipeline is doing.
![]()
One thing I’ll state at the start: this post, and the previous, have been quite a bit more in depth, even compared to other posts in this series. There is a reason for this: knowledge graphs and ontologies are currently one of the primary ways to keep an AI honest, as it were. Put another way, and put more accurately, these concepts are what allow for explainable AI and thus trustable AI. Explainable and trustable are two primary qualities that test specialists will be able to engage with to not only make themselves marketable (a personal goal) but also work in a context to ensure that the technocracy being built is not an entirely dehumanized one (a societal goal).
The pipeline we looked at constructed a knowledge graph from unstructured text, and the ontology is what gave that graph its structure. We defined the ontology upfront in the config.py file: the entity types, predicate categories, confidence levels, and source claim types. The extraction prompt used that ontology to constrain what the model pulled out of the text.
The graph was the result; the ontology was the scaffolding.
The pipeline from the first post is the system under test here. We’re not building it too much further, although there will be a few tactical changes. We’ll construct one new artifact by hand, a reference graph, which is the ground truth everything else gets measured against.
What you’ll be seeing here is the testing role even in the context of putative production code: deciding what correct looks like, making that decision explicit and structured, and using it to hold the system accountable. The prompt variants and evaluation code are the mechanisms. The reference graph is the judgment.
As any tester knows, in any testing effort, the hardest and most important work is always the judgment.
The Claim Worth Testing
The previous post ended with an assertion: that the knowledge graph pipeline’s failure modes are visible, debuggable, and correctable. The evidence offered was qualitative. The extraction produced verbose predicates. The model missed an implicit concept. The grounded answer correctly admitted it lacked sufficient information. These are observations about a single run, but observations are not a measurement.
That distinction matters more than it might seem. Without doubt, a pipeline you can observe is better than one you can’t. But a pipeline you can measure is better still, because measurement is what turns debugging from an art into a discipline. When you can assign a score to extraction quality, you can compare prompt variants systematically, track regressions when you change the model, and make an evidence-based case for why one configuration outperforms another.
That’s the difference between knowing something went wrong and knowing how wrong it went, and whether any given fixes actually helped.
The specific claim this post tests is the one the first post left implicit: that tightening the extraction prompt produces measurably better triples, and that better triples produce richer query results. The pipeline gives us two of those three things already. What it lacks is the measurement layer that connects prompt changes to extraction quality in a way that is reproducible and comparable across runs.
That measurement layer is what this post builds. The tool is DeepEval, which we’ve looked at quite a bit in this series. The metric is faithfulness, which we’ve also looked at.
And, as briefly mentioned in the last post, the recursive irony, which at this point is either delightful or exhausting depending on your tolerance for such things, is that we’re about to run a faithfulness evaluator against a pipeline built on a paper whose central argument is that revision in service of a community’s present need is itself an act of faithfulness.
For this post, the core code is stored in kgllm_v2 in the repo. I wanted to make sure the two experiments, between v1 and v2, were kept distinct.
For this post, and in the v2 section itself, config.py, queries.py, and graph.py do not change at all. There are some minimal changes to extraction.py and pipeline.py. There are two files added: evaluate1.py and evaluate2.py. I’ll cover all of this as we go.
The Ground Truth Problem
Okay, so orienting ourselves: the first post built a pipeline and ran it. The extraction produced seven triples from the Section II.C passage of the paper, the graph contained 85 RDF statements, and Query 3 returned nothing because the model did not extract “permission structure” as an explicit entity. Those observations were useful. They told us something was missing. What they could not tell us was how much was missing, or whether a different prompt would have captured it.
To measure extraction quality you need something to measure against. In machine learning terms this is a reference dataset, by which is meant a ground truth representation of what correct extraction looks like for a given input. For our pipeline, that means a hand-curated set of triples that a careful reader of Section II.C would say faithfully represents the passage’s entities and relationships.
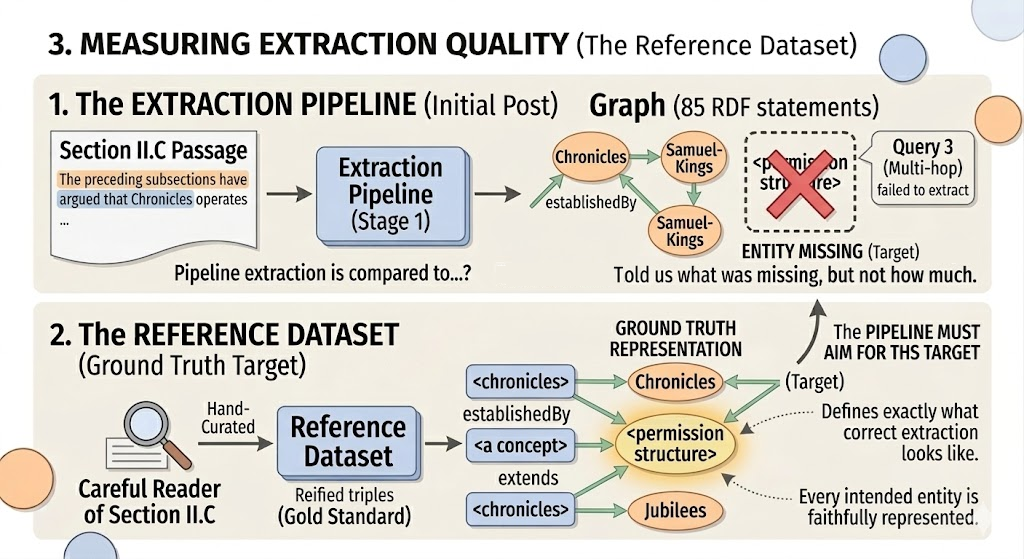
I say “hand-curated” to indicate that this is a human action. The temptation is to perhaps generate this reference with a model. The problem with that approach is circular: if the reference encodes the same extraction biases as the system being evaluated, the score tells you how consistently the model agrees with itself rather than how faithfully it represents the source text.
Ground truth needs to come from outside the system being measured. Here that means a human reader; specifically, the author of the paper, which in this case is a convenient happenstance, since the author of this post happens to be the author of the paper! Lucky us.
That said, you could take a stab at this yourself, of course. What you might want to do is look at what I generate and see if you agree, disagree or would have done it differently.
If you’re playing along and you have grabbed the kgllm_v2 code, add a file called reference.json to it with the following contents:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 |
{ "triples": [ { "subject": "Chronicles", "predicate": "revises", "object": "Samuel-Kings", "confidence": "high", "source_claim": "stated" }, { "subject": "Chronicles", "predicate": "draws_on", "object": "Numbers 22", "confidence": "high", "source_claim": "stated" }, { "subject": "permission structure", "predicate": "demonstrated_by", "object": "Chronicles", "confidence": "high", "source_claim": "inferred" }, { "subject": "satan", "predicate": "grounded_in", "object": "Numbers 22", "confidence": "high", "source_claim": "stated" }, { "subject": "Jubilees", "predicate": "extends", "object": "permission structure", "confidence": "medium", "source_claim": "inferred" }, { "subject": "4QSama", "predicate": "corroborates", "object": "Chronicles", "confidence": "high", "source_claim": "stated" }, { "subject": "Chronicler", "predicate": "grounds_revision_in", "object": "Balaam narrative", "confidence": "high", "source_claim": "stated" }, { "subject": "satan", "predicate": "functions_as", "object": "celestial provocateur", "confidence": "high", "source_claim": "stated" }, { "subject": "YHWH", "predicate": "remains", "object": "sovereign", "confidence": "high", "source_claim": "stated" }, { "subject": "Balaam narrative", "predicate": "structurally_parallels", "object": "census account", "confidence": "high", "source_claim": "stated" }, { "subject": "Stokes", "predicate": "identifies", "object": "structural parallels", "confidence": "high", "source_claim": "stated" }, { "subject": "1 Enoch", "predicate": "extends", "object": "permission structure", "confidence": "medium", "source_claim": "inferred" }, { "subject": "Chronicles", "predicate": "opens_space_for", "object": "Second Temple angelology", "confidence": "medium", "source_claim": "inferred" }, { "subject": "Chronicler", "predicate": "addresses", "object": "theodicy problem", "confidence": "high", "source_claim": "stated" }, { "subject": "canon", "predicate": "anchors", "object": "revision", "confidence": "high", "source_claim": "inferred" } ] } |
This hand-curated reference graph for Section II.C contains fifteen triples. I constructed this pretty much as you would: by reading the passage carefully and asking three questions for each candidate relationship: is this entity explicitly named in the text, is this relationship explicitly stated or does it require inference, and is this predicate drawn from the controlled vocabulary defined in the extraction prompt.
Triples that required inference were included but marked accordingly, because the evaluation should reward correct inferred triples rather than penalizing the model for doing interpretive work the prompt explicitly invited.
One thing worth being honest about: constructing this reference is itself an interpretive act. Deciding that “permission structure” belongs as an explicit entity even though the phrase appears only in the paper’s broader argument rather than in Section II.C directly is a judgment call. So is deciding that the Balaam narrative structurally parallels the census account rather than simply influencing it.
This notion of “interpretive act” is really important. The reference graph does not claim to be the only correct reading of the passage. It claims to be a careful one, constructed according to explicit criteria, against which the pipeline’s extraction can be scored consistently across prompt variants.
That consistency is what the reference makes possible. With it, we can run three prompt variants: the original from the first post, a version with tightened predicate vocabulary, and a version that explicitly names the permission structure concept. We can then ask a precise question: which prompt produces triples that most faithfully represent what the passage actually contains?
Three Prompt Variants
The first post identified three specific extraction artifacts in the baseline run: predicate labels that were verbose and inconsistent, an implicit concept (the permission structure) that the model did not extract because the phrase does not appear explicitly in Section II.C, and a citation used as an entity identifier rather than a clean label. Each of these is a correctable prompt engineering problem. The question is whether correcting them produces measurably better triples, and whether the corrections interact with each other in unexpected ways.
To answer that cleanly, I changed one thing at a time in the production code. I added three prompt variants, each building on the last, each with a specific hypothesis about what it will improve and what it might cost.
Variant 1: Baseline
This variant is actually the original prompt from the first post, unchanged. This is the control condition. It defines entity types, predicate categories, confidence levels, and source claim types, and it asks the model to reason before producing output. What it does not do is constrain predicate label length, specify preferred vocabulary, or name any concepts the model should watch for.
The expected behavior is exactly what the first post produced: coherent reasoning, reasonable entity identification, verbose and inconsistent predicate labels, and no extraction of the permission structure concept. The baseline exists not to perform well but to give the other variants something measurable to beat.
The only change for this second post is that the baseline prompt is now named explicitly in the code rather than being the default. In the v2 extraction.py, you’ll now see this:
|
1 2 3 4 5 |
PROMPT_VARIANTS = { "baseline": SYSTEM_PROMPT, "tighter_predicates": SYSTEM_PROMPT_V2, "concept_seeded": SYSTEM_PROMPT_V3, } |
Variant 2: Tighter Predicate Control
This variant adds a single instruction to the baseline prompt, inserted after the predicate category definitions. You will see this in the SYSTEM_PROMPT_V2:
When selecting predicate labels, prefer short labels of two to four
words drawn from the suggested vocabulary. Avoid sentence fragments,
gerund phrases, and citation strings as predicate labels. Examples
of preferred forms: "revises", "draws on", "grounds revision in",
"establishes", "extends", "influenced by".
Nothing else changes. The entity types, confidence levels, source claim types, and reasoning instruction are identical to the baseline.
The hypothesis is specific: this constraint reduces predicate verbosity and improves query consistency without significantly affecting which relationships the model identifies. A predicate like “features the angel of YHWH as an adversary” should collapse to something like “employs” or “draws on.” A citation string like “Stokes (2009)” used as a subject identifier should not be affected by this change at all. That’s an entity problem, not a predicate problem, which is why it is left for Variant 3.
If the hypothesis holds, Query 2 results should become more consistent across runs because argumentative relationships will share predicate labels rather than each being expressed in the model’s own words. If it does not hold, and thus if the model ignores the constraint or applies it inconsistently, that is itself a meaningful finding about the limits of prompt-level vocabulary control.
Variant 3: Concept Seeding
This variant adds a second instruction to the Variant 2 prompt, inserted after the predicate constraint. You can sees this in the SYSTEM_PROMPT_V3 portion.
The following concepts are central to this passage and should be
extracted as explicit entities if they are present or strongly
implied by the text:
- permission structure: the canonically grounded precedent for
reinterpreting authoritative texts under new circumstances
- intertextual reasoning: the practice of reading one canonical
text through the lens of another
- theodicy: the theological problem of reconciling divine
sovereignty with human suffering or error
- celestial provocateur: a heavenly agent who incites action
as an instrument of divine judgment
This variant changes both the predicate behavior inherited from Variant 2 and the entity identification behavior. The hypothesis is that explicit concept seeding recovers the implicit entities the baseline missed, particularly the permission structure, but at a possible cost: the model may over-extract concepts that are only weakly supported in the text, or force entities into the graph that belong to the paper’s broader argument rather than to Section II.C specifically.
That tension is worth watching for in the results. A concept like “permission structure” is central to the paper but appears in Section II.C as a demonstrated conclusion rather than a named entity. Seeding it explicitly asks the model to extract what the passage implies rather than only what it states. Whether that produces a more faithful graph or a more presumptuous one is exactly what the faithfulness score will tell us.
Measuring Extraction Quality with DeepEval
My earlier post on faithfulness established the core mechanic: extract truths from a retrieval context, decompose the generated answer into claims, and check each claim against the available truths. A faithful answer makes no claims that can’t be traced back to the source material.
That mechanic was designed for RAG evaluation, specifically for checking whether a model’s answer stays grounded in what the retriever provided. Here we’re pointing it at a different target, and the adaptation is worth being explicit about.
In a RAG faithfulness evaluation, the retrieval context is the source of truth and the generated answer is what gets scored. In our pipeline, the source passage plays the role of retrieval context and each extracted triple plays the role of a claim. The question we’re asking is not “did the model’s answer stay faithful to the retrieved chunks” but “did the model’s extracted triples stay faithful to the passage.” The machinery is identical. The target has shifted from answer evaluation to extraction evaluation.
This adaptation is defensible for a specific reason: a triple is an atomic claim in exactly the sense DeepEval’s faithfulness metric requires. “Chronicles revises Samuel-Kings” is a claim that can be checked directly against the passage. “The satan of 1 Chronicles 21 functions as a celestial provocateur” is a claim that can be checked directly against the passage. The truths DeepEval extracts from the passage become the ground against which each triple is scored, and the resulting faithfulness score tells us how well the extraction stayed within what the text actually supports rather than what the model inferred or invented.
The one honest caveat: DeepEval’s faithfulness metric does not distinguish between a triple that is unsupported because the model missed a relationship and one that is unsupported because the model hallucinated one. Both score the same way. That limitation matters less here than it would in a RAG context, because we have the reference graph we just created as a second signal.
The faithfulness score tells us how grounded the extraction is, and the reference comparison tells us what it missed.
All of this is provided in a new file in v2 called evaluate1.py.
A few things worth noting about this setup. The triple_to_claim() function converts each structured triple into a natural language claim string. This is the form DeepEval’s metric expects, and including the confidence and source fields means those metadata values are part of what gets evaluated rather than invisible to the scorer. The passage is passed as a single-element list in retrieval_context, which is the correct structure for DeepEval even when you have one source document rather than multiple retrieved chunks.
The evaluate_extraction() function returns a results dictionary rather than printing directly, because we will be calling it three times (once per variant), and comparing the scores in a summary table.
With these three pieces together — the helper functions, a compare_variants(), and a __main__ block — the file is fully runnable with the folowing:
python evaluate1.py python evaluate1.py --verbose
Here is some output:
Loaded passage: passage.txt (8145 characters)
Running all prompt variants...
Running variant: baseline
Extracted 10 valid triples (0 dropped).
Running variant: tighter_predicates
Extracted 5 valid triples (0 dropped).
Running variant: concept_seeded
Extracted 8 valid triples (0 dropped).
Evaluating variant: baseline
Evaluating variant: tighter_predicates
Evaluating variant: concept_seeded
============================================================
EXTRACTION FAITHFULNESS COMPARISON
============================================================
Variant: baseline
Triples extracted : 10
Faithfulness score: 0.56
Reason: The score is 0.56 because there are discrepancies between the actual output and the retrieval context regarding the attribution of the incitement for the census in both 2 Samuel and 1 Chronicles, as well as differences in the narrative borrowing and description of events.
Variant: tighter_predicates
Triples extracted : 5
Faithfulness score: 0.60
Reason: The score is 0.60 because the contradictions highlight discrepancies in how the actual output interprets the context, particularly regarding the function and role of the satan figure.
Variant: concept_seeded
Triples extracted : 8
Faithfulness score: 0.62
Reason: The score is 0.62 because the actual output incorrectly portrays Satan in 1 Chronicles 21:1 as an independent cosmic adversary, contradicting the retrieval context. Additionally, it falsely claims that Chronicles extends the Balaam Narrative and links Chronicles' revisions to the 4QSama Manuscript without direct evidence.
Reading the Results
The comparison table rewards careful reading. The headline numbers (0.56, 0.60, 0.62) tell a partial story, and the reasons tell the rest.
The first thing worth noting is the direction of the scores. Each prompt variant produces a modest faithfulness improvement over the previous one, which is the expected pattern: tighter predicate control helped, and concept seeding helped a little more. But the improvements are small, and all three scores sit in the same middling band. No variant broke 0.65. That’s not a failure of the prompt engineering. It’s a signal about where the extraction difficulty actually lies in this passage.
The reasons make that signal explicit. The baseline scored 0.56 with a reason pointing to “discrepancies in attribution of incitement for the census.” This is the satan revision at the heart of Section II.C: the passage is explicitly about the fact that 2 Samuel and 1 Chronicles attribute the incitement differently, and the model extracted triples that reflect that tension. The faithfulness metric, reading the passage as a single retrieval context, flagged those triples as contradictory because they appear to conflict with each other. Yet, they don’t conflict: they are the point! The passage is about the discrepancy, not despite it.
The tighter predicates variant scored 0.60, with the reason now focused specifically on “the function and role of the satan figure.” Constraining predicate vocabulary reduced some of the verbosity artifacts from the baseline, but it didn’t resolve the underlying issue: the satan figure in this passage is theologically complex, and the model’s extracted triples about its nature and function were scored against a passage that deliberately holds multiple characterizations of that figure in tension.
The concept seeded variant scored 0.62, and its reason is the most specific of the three. The metric flagged three problems: portraying Satan as an independent cosmic adversary, claiming Chronicles extends the Balaam narrative, and linking Chronicles’ revisions to 4QSama without direct evidence. The first of these is actually what the passage argues against! The Chronicler’s satan is explicitly not the independent cosmic adversary of later tradition. The second and third are inferred relationships that the concept seeding prompt invited the model to extract. Seeding the permission structure concept recovered implicit entities, as hypothesized, but it also encouraged the model to reach slightly beyond what the text directly supports.
What this pattern reveals is something the first post gestured at qualitatively but could not measure: the extraction difficulty in this passage is not primarily about predicate vocabulary or concept coverage. It’s about the passage’s argumentative structure. Section II.C builds its argument by holding contradictory claims in tension and then resolving them. A model extracting triples from that kind of text will naturally produce triples that look contradictory to a faithfulness metric reading the same text as a flat retrieval context.
Key point: the metric is working correctly! It’s doing exactly what we saw it do in the warp drive example from the earlier posts. The passage we’re looking at is just harder than a straightforward factual source.
That finding is itself worth something. It tells you that faithfulness scoring is most reliable when the source text makes claims rather than analyzes them. For argumentative scholarly prose, you would want to either segment the passage into claim-level chunks before extraction, or use a reference graph comparison as the primary signal and faithfulness scoring as a secondary one. Which is exactly what having both tools in the pipeline makes possible.
Do you now start to see why LLMs can hallucinate or get facts wrong, even with source material on hand? And imagine how much more complicated that gets when LLMs grab multiple source materials. What testing is doing here is exposing a reality but giving an ability to prove it. Contrast that with a lot of the argumentation you see online.
Given where we are, the next step is the reference graph comparison and showing how the reference triples we hand-curated score against what each variant actually extracted.
A Second Signal: Reference Graph Comparison
For this, we can consider the new v2 file called evaluate2.py.
The faithfulness scores told us something useful: all three variants produce extractions that are moderately grounded in the passage, with modest improvements as the prompt tightens. What they did not tell us is what each variant missed, or whether the triples it did extract were the right ones.
That latter is a different question, and it needs a different measurement. Faithfulness scoring asks “are these triples supported by the passage.” Reference comparison asks “do these triples match what a careful reader would have extracted.” The first is a grounding question. The second is a coverage and precision question. You need both to get a complete picture of extraction quality.
The reference graph we constructed earlier is what makes this measurement possible. Fifteen hand-curated triples representing a careful reading of Section II.C, constructed according to explicit criteria: is this entity explicitly named, is this relationship stated or inferred, is this predicate drawn from the controlled vocabulary. That reference is now the ground truth against which each variant’s extraction gets scored.
Crucially, the scoring produces three numbers per variant.
- Recall measures what fraction of the reference triples the extraction captured. A recall of 0.60 means the variant found nine of the fifteen reference triples and missed six. Low recall tells you the extraction is incomplete; relationships a careful reader would consider central are not making it into the graph.
- Precision measures what fraction of the extracted triples appear in the reference. A precision of 0.60 means six out of every ten triples the model extracted were ones our reference validates. Low precision tells you the extraction is noisy; the model is finding relationships, but not necessarily the right ones.
- F1 is the harmonic mean of the two, which penalizes variants that optimize one at the expense of the other. A variant that extracts every possible triple will have perfect recall but poor precision. A variant that extracts only one perfectly matching triple will have perfect precision but poor recall. F1 rewards the variant that gets both right simultaneously.
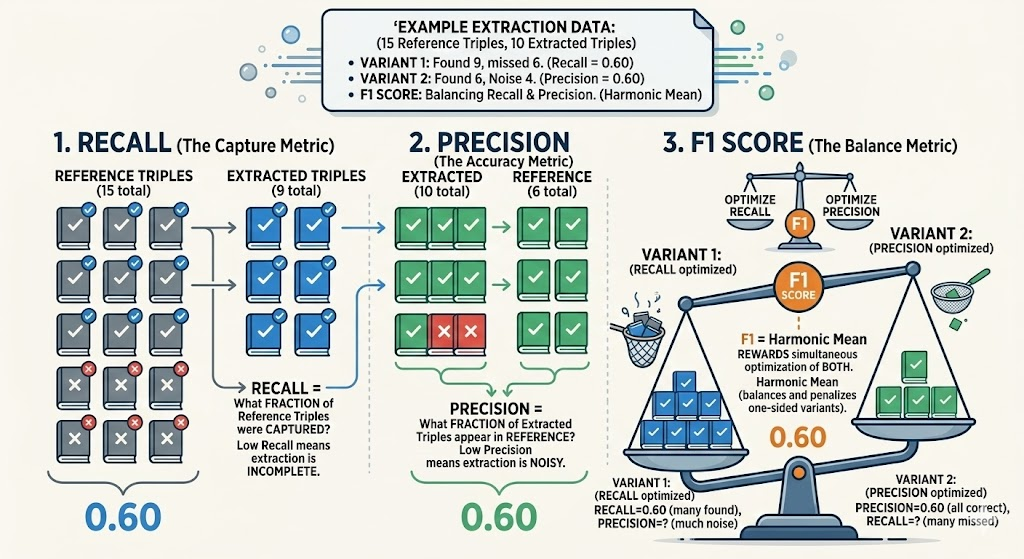
Together with the faithfulness score, these three numbers give you a complete diagnostic picture for each variant. Faithfulness tells you how grounded the extraction is. Recall tells you how much it missed. Precision tells you how much noise it added. And the missed and extra triple lists make those abstract numbers concrete: you can see exactly which relationships each variant failed to capture and which ones it invented.
That diagnostic completeness is the point. A pipeline you can measure at this level of detail is one you can improve systematically rather than by intuition.
As before, you can run the evaluate script:
python evaluate2.py python evaluate2.py --verbose
Here is some output:
Loaded passage : passage.txt (8145 characters)
Running all prompt variants...
Running variant: baseline
Extracted 6 valid triples (0 dropped).
Running variant: tighter_predicates
Extracted 9 valid triples (0 dropped).
Running variant: concept_seeded
Extracted 4 valid triples (0 dropped).
Reference graph loaded: 15 triples
Evaluating variant: baseline
Evaluating variant: tighter_predicates
Evaluating variant: concept_seeded
============================================================
EXTRACTION EVALUATION SUMMARY
============================================================
Variant : baseline
Triples : 6 extracted, 1 matched reference
Faithfulness : 0.67
Recall : 0.07
Precision : 0.17
F1 : 0.10
Missed (14):
Chronicles --[draws_on]--> Numbers 22
permission structure --[demonstrated_by]--> Chronicles
satan --[grounded_in]--> Numbers 22
Jubilees --[extends]--> permission structure
4QSama --[corroborates]--> Chronicles
Chronicler --[grounds_revision_in]--> Balaam narrative
satan --[functions_as]--> celestial provocateur
YHWH --[remains]--> sovereign
Balaam narrative --[structurally_parallels]--> census account
Stokes --[identifies]--> structural parallels
1 Enoch --[extends]--> permission structure
Chronicles --[opens_space_for]--> Second Temple angelology
Chronicler --[addresses]--> theodicy problem
canon --[anchors]--> revision
Extra (5):
2 Samuel 24:1 --[opens with]--> YHWH's incitement of David due to divine anger against Israel
1 Chronicles 21:1 --[opens with]--> a satan inciting David to count the people of Israel and Judah
1 Chronicles 21:1 --[grounds revision in canonical structure]--> Balaam narrative of Numbers 22:22-23
4QSama (Qumran manuscript) --[provides evidence for canonical origin of Chronicles revision]--> 1 Chronicles 21:1
Chronicles --[extends interpretive tradition]--> Second Temple literature
Variant : tighter_predicates
Triples : 9 extracted, 1 matched reference
Faithfulness : 0.56
Recall : 0.07
Precision : 0.11
F1 : 0.08
Missed (14):
Chronicles --[draws_on]--> Numbers 22
permission structure --[demonstrated_by]--> Chronicles
satan --[grounded_in]--> Numbers 22
Jubilees --[extends]--> permission structure
4QSama --[corroborates]--> Chronicles
Chronicler --[grounds_revision_in]--> Balaam narrative
satan --[functions_as]--> celestial provocateur
YHWH --[remains]--> sovereign
Balaam narrative --[structurally_parallels]--> census account
Stokes --[identifies]--> structural parallels
1 Enoch --[extends]--> permission structure
Chronicles --[opens_space_for]--> Second Temple angelology
Chronicler --[addresses]--> theodicy problem
canon --[anchors]--> revision
Extra (8):
Satan in 1 Chronicles 21:1 --[replaces]--> YHWH in 2 Samuel 24:1
Satan in 1 Chronicles 21:1 --[grounds revision in]--> Balaam story in Numbers 22
Balaam story in Numbers 22 --[parallels]--> Census account in 2 Samuel 24:1
Satan in 1 Chronicles 21:1 --[functions as]--> celestial provocateur
4QSama --[closely analogs]--> Balaam scene in Numbers 22
4QSama --[provides evidence for]--> convergence of census with Balaam story
Chronicles --[grounds authority in]--> canonically anchored revisions
Satan in 1 Chronicles 21:1 --[opens space for]--> heavenly adversary expansion
Variant : concept_seeded
Triples : 4 extracted, 0 matched reference
Faithfulness : 0.50
Recall : 0.00
Precision : 0.00
F1 : 0.00
Missed (15):
Chronicles --[revises]--> Samuel-Kings
Chronicles --[draws_on]--> Numbers 22
permission structure --[demonstrated_by]--> Chronicles
satan --[grounded_in]--> Numbers 22
Jubilees --[extends]--> permission structure
4QSama --[corroborates]--> Chronicles
Chronicler --[grounds_revision_in]--> Balaam narrative
satan --[functions_as]--> celestial provocateur
YHWH --[remains]--> sovereign
Balaam narrative --[structurally_parallels]--> census account
Stokes --[identifies]--> structural parallels
1 Enoch --[extends]--> permission structure
Chronicles --[opens_space_for]--> Second Temple angelology
Chronicler --[addresses]--> theodicy problem
canon --[anchors]--> revision
Extra (4):
Chronicles --[revises]--> 2 Samuel 24:1
satan --[grounds revision in]--> Balaam narrative (Numbers 22:22)
Chronicles --[extends]--> satan
Chronicles --[influences]--> Later Second Temple Literature (Jubilees, 1 Enoch, Testament of Job)
Reading the Results
The numbers here demand careful attention because the pattern they reveal runs counter to the intuition that more prompt engineering produces better extraction.
The baseline variant extracted six triples, matched one reference triple, and produced a recall of 0.07 and precision of 0.17. Those are low scores, but the faithfulness score of 0.67 is the highest of the three variants. That combination of reasonable grounding with poor coverage tells you the baseline was conservative and careful about what it extracted, but it was not extracting the right things.
The tighter predicates variant extracted nine triples, also matched one reference triple, and produced lower scores across the board: recall 0.07, precision 0.11, F1 0.08, faithfulness 0.56. More triples, same number of matches, lower faithfulness. Interesting! The predicate constraint loosened something rather than tightening it. By that I mean, the model extracted more relationships but they were noisier and less grounded.
Looking at the extra triples list makes this concrete: “Satan in 1 Chronicles 21:1 –[closely analogs]–> Balaam scene in Numbers 22” is a reasonable relationship but “closely analogs” is not a controlled predicate. The constraint influenced label form but not label discipline.
The concept seeded variant is the most striking result. Four triples extracted, zero matched, recall and precision both 0.00. The concept seeding instruction did not recover the implicit entities as hypothesized. In fact, it appears to have destabilized the extraction entirely! Looking at what it produced: “Chronicles –[extends]–> satan” is not a relationship the passage supports in any reading. “Chronicles –[revises]–> 2 Samuel 24:1” is close to the reference triple “Chronicles –[revises]–> Samuel-Kings” but the object label mismatch means it scores zero.
That near-miss is worth pausing on. The normalization logic treats “2 Samuel 24:1” and “Samuel-Kings” as different entities, which they are, but a human reader would recognize the relationship as essentially correct. The reference comparison is exact where human judgment would be approximate.
That observation points to something worth being honest about here in the context of what this post is showing you: the reference comparison scoring is only as good as the normalization logic, and snake-case normalization is a blunt instrument. “Satan in 1 Chronicles 21:1” and “satan” refer to the same entity but score as different. “Grounds revision in” and “grounds_revision_in” normalize correctly but “closely analogs” and “structurally_parallels” do not match even though they describe the same relationship. A production evaluation system would use fuzzy string matching or embedding similarity for the comparison rather than normalized exact match.
The missed triples list is consistent across all three variants: fourteen of the same fifteen reference triples appear as missed in both baseline and tighter predicates, and all fifteen in concept seeded. That consistency is telling. The missed relationships are not randomly distributed. They cluster around the argumentative and inferred triples in the reference: “permission structure –[demonstrated_by]–> Chronicles,” “canon –[anchors]–> revision,” “YHWH –[remains]–> sovereign.” These are the relationships that require interpretive synthesis rather than direct reading, and no prompt variant recovered them reliably.
What this run demonstrates is something the faithfulness scores hinted at but could not show directly: the extraction difficulty in this passage is structural, not prompt-level. The argumentative and inferred relationships that make the passage intellectually rich are precisely the ones that resist extraction. Prompt engineering can influence predicate vocabulary and entity coverage at the margins, but recovering the passage’s interpretive claims requires something the current extraction approach does not provide: either a more targeted prompt that explicitly asks for argumentative synthesis, or a multi-pass extraction that separates stated relationships from inferred ones and handles each differently.
In fact, those would the natural next experiments. And having three scored variants with complete missed and extra triple lists means you know exactly what to target.
That’s a key point here. All good testing, like all good experiments, should point to the next testing to run; the next experiment to perform.
Pipeline
If you remember from the first post, the pipeline code is what runs everything together. Here there is a v2 pipeline.py. With all of the above changes in place, the three primary run modes are:
# Original four-stage run, unchanged behavior python pipeline.py # Four-stage run with graph saved python pipeline.py --save-graph # Full five-stage run with evaluation python pipeline.py --evaluate # Full five-stage run with custom reference python pipeline.py --evaluate --reference my_reference.json
One thing worth confirming before you run it: the compare_variants() function the evaluate files runs all three prompt variants from scratch, which means Stage 5 will call the model three additional times. That’s intentional because the evaluation is measuring the variants independently of whatever the pipeline extracted in Stage 1. I’m calling it out here so you understand why Stage 5 takes longer than the other stages.
Here is some potential output:
============================================================
STAGE: 1 of 5 — Triple Extraction
============================================================
Loaded passage: passage.txt (8145 characters)
Sending passage to model for triple extraction...
Model: qwen2.5:latest
Extracted 10 valid triples (0 dropped).
Reasoning trace (first 400 chars):
This passage discusses the textual and theological
revisions made in Chronicles to reframe the account of
David's census. It focuses on how Chronicles introduces
a 'satan' figure to explain divine judgment, drawing on
parallels with the Balaam narrative in Numbers. The text
highlights how these changes are grounded within the
canon and influence later literature.
Triples extracted: 10
============================================================
STAGE: 2 of 5 — Graph Construction
============================================================
Building RDF graph from extracted triples...
Graph constructed: 108 RDF statements.
--- GRAPH SUMMARY ---
Total RDF statements: 108
Entity types:
kg:Text: 6
kg:Concept: 3
kg:Person: 1
---------------------
============================================================
STAGE: 3 of 5 — SPARQL Queries
============================================================
Running Query 1: Entity Neighborhood (Chronicles)...
[Q1 — Entity Neighborhood] — 1 result(s):
1. target: 2 Samuel 24:1 | predicate: revises | category: textual
Running Query 2: Argumentative Triples...
[Q2 — Argumentative Triples] — 2 result(s):
1. subject: 1 Chronicles 21:1 | predicate: authorizes | object: Balaam Narrative | confidence: high
2. subject: Satan | predicate: establishes | object: Divine Permission Structure | confidence: high
Running Query 3: Multi-hop from Permission Structure...
[Q3 — Multi-hop Traversal]: No results found.
Running Query 4: Inferred Triples...
[Q4 — Inferred Triples] — 1 result(s):
1. subject: 4QSama | predicate: preceded Chronicles | object: Chronicles | section: II.C
============================================================
STAGE: 4 of 5 — Grounded Answer
============================================================
Question:
Based on the knowledge graph, what is the relationship between Chronicles and the permission structure, and which later texts are connected to that structure through the graph?
Sending query results to model for grounded answer...
============================================================
ANSWER (grounded in graph query results)
============================================================
Based on the provided query results from the structured
knowledge graph, there is a relationship between
Chronicles and the permission structure through the Divine
Permission Structure being established by Satan (Query 2).
Specifically: 1. **Satan establishes the Divine
Permission Structure**: According to Query 2, "Satan"
establishes the "Divine Permission Structure." This
suggests that Satan plays an authoritative role in setting
up this structure. 2. **Later texts connected to the
permission structure through Chronicles**: The entity
"Chronicles" is mentioned indirectly via its predecessor
text 4QSama (Query 4). Query 4 indicates that "4QSama"
preceded "Chronicles," and while it does not directly
connect 4QSama with the Divine Permission Structure, it
provides a link between the permission structure and
Chronicles through their shared historical context. The
query results do not provide direct evidence of which
later texts are explicitly connected to this permission
structure via Chronicles. However, we can infer that any
texts that chronologically follow Chronicles in the graph
might be indirectly related due to the established
permission structure. In summary: - **Satan establishes
the Divine Permission Structure** (Query 2). -
**Chronicles have a connection through their predecessor
text 4QSama**, which suggests an indirect relationship
with the Divine Permission Structure (Query 4). The
results do not provide direct evidence of later texts
connected to this permission structure via Chronicles, but
they set up a framework for such connections.
============================================================
============================================================
STAGE: 5 of 5 — Extraction Evaluation
============================================================
Running faithfulness and reference comparison...
Reference: \mnt\blog-ai-testing\kgllm_v2\reference.json
Running all prompt variants...
Running variant: baseline
Extracted 11 valid triples (0 dropped).
Running variant: tighter_predicates
Extracted 6 valid triples (0 dropped).
Running variant: concept_seeded
Extracted 8 valid triples (0 dropped).
Reference graph loaded: 15 triples
Evaluating variant: baseline
Evaluating variant: tighter_predicates
Evaluating variant: concept_seeded
============================================================
EXTRACTION EVALUATION SUMMARY
============================================================
Variant : baseline
Triples : 11 extracted, 0 matched reference
Faithfulness : 0.73
Recall : 0.00
Precision : 0.00
F1 : 0.00
Missed (15):
Chronicles --[revises]--> Samuel-Kings
Chronicles --[draws_on]--> Numbers 22
permission structure --[demonstrated_by]--> Chronicles
satan --[grounded_in]--> Numbers 22
Jubilees --[extends]--> permission structure
4QSama --[corroborates]--> Chronicles
Chronicler --[grounds_revision_in]--> Balaam narrative
satan --[functions_as]--> celestial provocateur
YHWH --[remains]--> sovereign
Balaam narrative --[structurally_parallels]--> census account
Stokes --[identifies]--> structural parallels
1 Enoch --[extends]--> permission structure
Chronicles --[opens_space_for]--> Second Temple angelology
Chronicler --[addresses]--> theodicy problem
canon --[anchors]--> revision
Extra (11):
Chronicles --[revises]--> Samuel
Satan --[replaces]--> YHWH
2 Samuel 24:1 --[opens with]--> YHWH inspires David to count the people of Israel and Judah
1 Chronicles 21:1 --[opens with]--> Satan inspires David to count the people of Israel
1 Chronicles 21:1 --[imports from]--> Numbers 22:22
Numbers 22:22 --[denotes satanic agent]--> angel of YHWH
4QSama --[shares with]--> 1 Chronicles 21:1
4QSama --[parallels]--> Numbers 22:22
Chronicles --[extends]--> Balaam narrative of Numbers 22:22
Chronicles --[opens permission structure]--> Balaam narrative of Numbers 22:22
Chronicles --[grounds in canonically anchored text]--> Balaam narrative of Numbers 22:22
Variant : tighter_predicates
Triples : 6 extracted, 0 matched reference
Faithfulness : 1.00
Recall : 0.00
Precision : 0.00
F1 : 0.00
Missed (15):
Chronicles --[revises]--> Samuel-Kings
Chronicles --[draws_on]--> Numbers 22
permission structure --[demonstrated_by]--> Chronicles
satan --[grounded_in]--> Numbers 22
Jubilees --[extends]--> permission structure
4QSama --[corroborates]--> Chronicles
Chronicler --[grounds_revision_in]--> Balaam narrative
satan --[functions_as]--> celestial provocateur
YHWH --[remains]--> sovereign
Balaam narrative --[structurally_parallels]--> census account
Stokes --[identifies]--> structural parallels
1 Enoch --[extends]--> permission structure
Chronicles --[opens_space_for]--> Second Temple angelology
Chronicler --[addresses]--> theodicy problem
canon --[anchors]--> revision
Extra (6):
Chronicles --[revises]--> Second Samuel 24:1
Chronicles --[grounds revision in]--> Numbers 22
Satan --[grounds revision in]--> Numbers 22 Balaam narrative
4QSama --[parallels]--> Numbers 22 Balaam narrative
Chronicles --[extends]--> Second Samuel 24:1
Second Temple Literature --[receives by]--> Chronicles
Variant : concept_seeded
Triples : 8 extracted, 1 matched reference
Faithfulness : 0.62
Recall : 0.07
Precision : 0.12
F1 : 0.09
Missed (14):
Chronicles --[revises]--> Samuel-Kings
Chronicles --[draws_on]--> Numbers 22
permission structure --[demonstrated_by]--> Chronicles
satan --[grounded_in]--> Numbers 22
Jubilees --[extends]--> permission structure
4QSama --[corroborates]--> Chronicles
Chronicler --[grounds_revision_in]--> Balaam narrative
YHWH --[remains]--> sovereign
Balaam narrative --[structurally_parallels]--> census account
Stokes --[identifies]--> structural parallels
1 Enoch --[extends]--> permission structure
Chronicles --[opens_space_for]--> Second Temple angelology
Chronicler --[addresses]--> theodicy problem
canon --[anchors]--> revision
Extra (7):
Chronicles --[revises]--> 2 Samuel 24:1
1 Chronicles 21:1 --[revises]--> 2 Samuel 24:1
Satan --[replaces]--> YHWH
1 Chronicles 21:1 --[grounds revision in]--> Numbers 22
Chronicles --[extends]--> permission structure
permission structure --[grounds revision in]--> 1 Chronicles 21:1
Chronicles --[influences]--> Second Temple literature
============================================================
Pipeline complete.
Triples extracted : 10
RDF statements : 108
Query 1 results : 1
Query 2 results : 2
Query 3 results : 0
Query 4 results : 1
Reading the Full Pipeline Output
The five-stage run reveals something that a standalone evaluation pass generally can’t: the relationship between what Stage 1 extracts in a given run and what Stage 5 measures across all three variants. These are independent processes in that Stage 1 ran the baseline prompt once, while Stage 5 ran all three variants separately. Comparing them is itself informative.
Stage 1 extracted ten triples this run, producing three Concept entities where the previous run produced one. The reasoning trace is notably better: “it focuses on how Chronicles introduces a ‘satan’ figure to explain divine judgment, drawing on parallels with the Balaam narrative in Numbers” is a precise characterization of what Section II.C is doing. The model is reading the passage correctly at the reasoning level.
The gap between good reasoning and good extraction is exactly the diagnostic the evaluation stage is designed to surface.
Query 2 produced an interesting result: “Satan establishes the Divine Permission Structure” with high confidence. The permission structure appeared as an extracted entity this run (as “Divine Permission Structure”) which is close to the reference triple “permission structure –[demonstrated_by]–> Chronicles” but inverted. The model found the concept but got the relationship direction entirely wrong! That’s a different kind of extraction error than missing the entity entirely, and it’s worth noting explicitly.
The grounded answer this run is weaker than the previous run despite the richer extraction. The reason is visible in Query 2: “Satan establishes the Divine Permission Structure” led the model to construct an answer where Satan plays an authoritative role in setting up the structure, which is a misreading the graph itself introduced. This is the pipeline’s failure mode made concrete. A wrong triple produces a wrong answer, and the grounded answer system has no way to detect that the triple was wrong. It can only work with what the graph contains.
Now the evaluation stage results, which are the most analytically interesting output in the entire post.
The tighter predicates variant scored a perfect 1.00 faithfulness with zero recall and zero precision. That combination deserves a careful reading because it looks completely paradoxical.
Perfect faithfulness means every claim the model made was grounded in the passage. Zero precision means none of those claims matched the reference. Both scores are correct simultaneously. The model extracted relationships that are genuinely present in the text, just not the ones the reference prioritized. Looking at the extra triples list confirms this: “Chronicles –[grounds revision in]–> Numbers 22” and “4QSama –[parallels]–> Numbers 22 Balaam narrative” are both defensible readings of the passage. They’re not wrong. They’re just expressed differently from the reference.
This is the most important finding in the entire evaluation run, and it deserves to be stated plainly: a perfect faithfulness score is compatible with zero reference match. The two metrics are measuring genuinely different things. Faithfulness measures grounding. Reference comparison measures alignment with a specific reading. A extraction can be perfectly grounded and still miss everything a human curator considered essential. That’s not a flaw in either metric; it’s what having two complementary signals actually means.
The concept seeded variant matched one reference triple this run (“satan –[functions_as]–> celestial provocateur”) which it missed in the previous evaluation run. That single match produced recall of 0.07, precision of 0.12, and F1 of 0.09. The extra triples list shows why precision is low: the model extracted “Chronicles –[extends]–> permission structure” and “permission structure –[grounds revision in]–> 1 Chronicles 21:1,” both of which reflect the concept seeding working as intended, but neither matches the reference exactly. The seeding recovered the permission structure concept but could not align its relationships with the reference formulation.
The baseline variant scored 0.73 faithfulness (the highest grounding score across both evaluation runs!) with zero reference match. Eleven triples extracted, none matching. The extra triples list shows why: “Chronicles –[revises]–> Samuel” is one small bit away from the reference triple “Chronicles –[revises]–> Samuel-Kings” but scores zero because the normalization treats them as different entities. That near-miss is the normalization limitation made visible in a concrete example.
What both evaluation runs together demonstrate is a finding worth stating as the central conclusion of this post: extraction quality cannot be measured with a single metric. Faithfulness tells you whether the model stayed within the passage. Reference comparison tells you whether it found what matters. Triple count tells you how much it produced. You need all three to understand what a prompt variant actually does. And even with all three, the normalization gap between “Samuel” and “Samuel-Kings” reminds you that automated scoring is an approximation of human judgment, not a replacement for it.
And, right there, you have a working example that shows why human judgment, and thus non-automated testing, is absolutely and definitively required in an AI context.
A Note on Scoring Limitations
The evaluation pipeline we looked at in this post makes automated measurement possible, but automated measurement has edges worth being explicit about.
The reference comparison uses normalized exact matching. Two strings are considered the same if they produce identical output after lowercasing, stripping whitespace, and replacing hyphens and spaces with underscores. That’s a blunt instrument, to say the least. “Samuel” and “Samuel-Kings” don’t match. “Grounds revision in” and “grounds_revision_in” do match. “Structurally parallels” and “closely analogs” do not match, even though a human reader would recognize them as describing the same relationship. Every zero-recall result in this post contains at least one near-miss of this kind, and the scores should be read with that in mind.
The faithfulness metric has its own approximation. DeepEval’s faithfulness was designed for RAG answer evaluation and we adapted it for extraction evaluation by treating each triple as a claim and the passage as retrieval context. That adaptation is defensible but not perfect. The metric can’t distinguish between a triple that is unsupported because the model hallucinated a relationship and one that’s unsupported because the model correctly identified an inferred relationship the passage implies but doesn’t state. Both score the same way. The confidence and source claim metadata in the triple schema was designed precisely to carry that distinction, but the current evaluation pipeline doesn’t pass those fields to the faithfulness scorer in a way that influences the verdict.
Thus, as a tester, my recommendation to my team would be that a more sophisticated evaluation system would address both limitations. Fuzzy string matching or embedding similarity would close the normalization gap, in that two strings describing the same relationship would score as a match even if their surface forms differ. A faithfulness scorer that treats inferred triples differently from stated ones would better reflect the extraction schema’s intent.
This is the value that I, as a tester of AI technology, bring to the table. Both of the above proposals are tractable improvements, and the pipeline’s modular structure — which, ideally, I’ve worked with the developers on — means either could be added to the evaluate modules without touching the other files.
I hasten to add that everything I’ve said here doesn’t amount to reasons to distrust the scores. Instead, they are reasons to read them as directional signals rather than precise measurements. We’ve seen a pattern across variants: consistent missed triples, the faithfulness and recall independence, the near-misses that score zero. That pattern is real and informative regardless of where the exact numbers land. The limitation is in the precision of the measurement, not in what the measurement reveals.
What This Post Demonstrated
The first post built a pipeline and observed its behavior. This post measured it, and the measurement revealed things observation alone could not.
Remember those qualities of testability: observability and controllabilty. We’ve provided both in this context. I talked about these concepts in another series, specifically on the spectrum of AI testing.
The most important finding is structural: the extraction difficulty in Section II.C is not primarily a prompt engineering problem. Fourteen of fifteen reference triples were missed consistently across all three variants and across multiple runs. Those missed triples are not randomly distributed. They cluster around the argumentative and inferred relationships that make the passage intellectually rich: “permission structure –[demonstrated_by]–> Chronicles,” “canon –[anchors]–> revision,” “YHWH –[remains]–> sovereign.” These are the relationships that require interpretive synthesis rather than direct reading, and no amount of predicate constraint or concept seeding recovers them reliably. The passage resists extraction at exactly the points where it’s (arguably) most interesting.
The second finding is methodological: faithfulness and reference comparison are complementary signals, not alternatives. The tighter predicates variant scored a perfect 1.00 faithfulness with zero reference match. That result is not a paradox; it’s what two genuinely different measurements look like when they point in different directions. Faithfulness tells you whether the model stayed within the passage. Reference comparison tells you whether it found what matters. You need both to understand what a prompt variant actually does.
The third finding is about the pipeline itself. A wrong triple in Stage 1 produced a wrong answer in Stage 4: the “Satan establishes the Divine Permission Structure” extraction led the grounded answer to construct a theologically inverted reading of the passage. The pipeline can’t detect that the triple was wrong. It can only work with what the graph contains. That’s the fundamental limitation of grounded answer systems, and seeing it made concrete in a specific run is more instructive than any abstract description of the failure mode would be.
The natural next experiments follow directly from these findings. A multi-pass extraction that separates stated relationships from inferred ones and handles each with a different prompt would target the missed argumentative triples more precisely. Embedding similarity matching in the reference comparison would close the normalization gap and surface the near-misses that currently score zero. A faithfulness scorer that weights inferred triples differently would better reflect the extraction schema’s intent.
And, again, I’ll point out that each of those is a one-variable change against a pipeline whose stages are independently testable. Which is, in the end, the argument this series has been making from the beginning: the value of a structured pipeline is not just what it produces. It’s what it makes measurable, and therefore improvable.
As I point out in the paper we used for these posts, the Chronicler revised Samuel-Kings because his community’s present need required a new engagement with inherited tradition. This pipeline revises its own outputs for the same reason: because measurement reveals where the current engagement falls short, and revision is how you close the gap. The method remains the same. Similarly, acting as a type of “Chronicler” myself, I’m revising some test knowledge in terms of my community’s present need, which is an increasingly AI-driven technocracy.
Next Steps!
This, along with the previous two posts, was a fairly in-depth look at knowledge graphs and ontologies. However, even with that, it was a very constrained example that really didn’t put too much emphasis on the ontology part with a real example. The next post will do just that.

Hi Jeff,
My 2 runs with just the faithfulness evaluation (evaluate1.py) produced scores of
Run 1 = 0.78,0.60,0.75
Run 2 = 0.67,0.50,0.83 across the 3 variants which seems to indicate concept seeding was working well.
This is contradicting the output you got (0.56, 0.60, 0.62).
Did you also notice better scores in other runs?