This series will be part of my ongoing topic around machine learning. In these posts my goal is to allow you to deep dive into a common example for those first starting out in the subject. By the end of these posts you will have written and tested a neural network to solve a classification and prediction problem and come away with some understanding of a fast-growing trend in the industry.
My hope, and my goal, is that these posts will be relevant to anyone who wants to get involved in machine learning. Obviously one of my core focal points is that of testing and those who practice the discipline. Right now there is a lot of work being done in machine learning around test supporting tools.
I actually find this a very positive development but very little of that is being driven by testers, which, unfortunately, matches what we saw with the agile movement, the DevOps movement, the TDD movement, the BDD movement, etc.
Thus I’m hoping testers will try and get ahead of the game a little and make sure they level-up their skills, having some input into a future that will see more computation placed in the context of artificial learners. These posts are my attempt to apply that hope to myself.
The Intersection of Testing and AI
I’ll start this off with a quote from the book Introduction to Deep Learning: Business Applications for Developers:
“Deep learning has taken artificial intelligence by storm and has infiltrated almost every business application. … A vast amount of data is available for exploration by machine learning algorithms. However, traditional machine learning techniques struggle to explore the intricate relationships presented in this so-called Big Data.”
The bolded emphasis there is mine.
The reason I bring that up is because today it’s getting harder to find any AI-based technology that does not rely on deep learning. Deep learning is focusing on where artificial intelligence drops down to machine learning which, in turn, drops down to neural networks as a primary algorithm. This is a context that testing, as a discipline, is already operating within to a great extent. This is a context that specialist testers, carrying out the methods of that discipline, will have to become more conversant with and certainly more proficient with.
From a testing standpoint — whether that be a human testing an AI or a human using an AI-based testing tool — this deep learning approach should be of interest.
Also of note in the above quote is the recognition that this deep learning technology has “infiltrated almost every business application.”
Some of these “infiltrations” are very visible: Google Translate, Amazon Alexa, Apple Siri, Microsoft Cortana, autonomous cars, and facial recognition. Others are less immediately visible but no less present: profiling mechanisms, targeted ad distribution, talent acquisition, credit and loan approvals, bank-to-insurance portals, hedge fund operation, anticipatory shopping, inventory management, and drug discovery and efficacy.
All of that technology, and its infusion into our society, means there is a very important ethical component to this. Developers and testers need to make sure that they can carry out their discipline in such a way that it is truth-preserving, value-adding, and human-focused. This is particularly the case as humans are more and more determining value by relying on technology to give them some notion of truth.
Okay, let’s dig in …
It’s About Lines
Looked at in one way, machine learning is concerned with the task of drawing lines. These lines can help provide boundaries that allow us to make decisions about data. As such, these lines are often called decision boundaries.
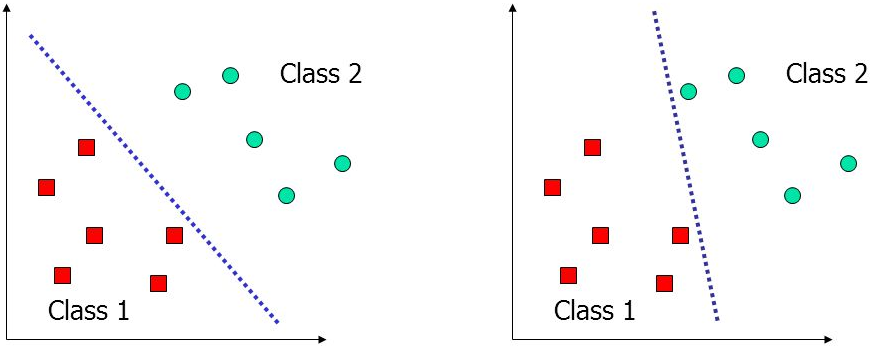
The simple idea being that we take some data and run a machine learning algorithm against it. That algorithm draws decision boundaries within the data, essentially separating the data into classes, as you can see above. Assuming this is successfully done, the algorithm can then extrapolate what has been learned to completely new data that hasn’t been seen before.
These lines that I’m describing are generally called classifiers or predictors.
It’s About Classifying and Predicting
So, looked at in a related way, machine learning is really concerned about classification and prediction. Sometimes we refer to the “prediction” as regression.
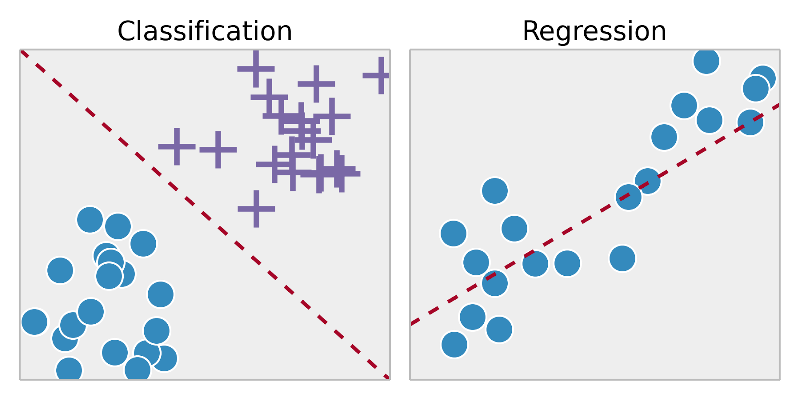
It’s About Recognizing Patterns
And looked at in yet another related way, machine learning is really just about pattern recognition. Machine learning algorithms learn patterns by drawing lines through data and then generalizing the patterns discovered to new data.
It’s About Minimizing Loss Along Gradients
Huh? I bet you felt pretty good about the above, right? And then I bring up minimizing loss along gradients, which can seem entirely non-sensical. And that’s the interesting thing about machine learning. Sometimes you get an effect similar to what Douglas Adams once described:
“When you’re cruising down the road in the fast lane and you lazily sail past a few hard-driving cars and are feeling pretty pleased with yourself and then accidentally change down from fourth to first instead of third thus making your engine leap out of your hood in a rather ugly mess, it tends to throw you off stride…”
I wanted to give you a little taste of that here.
So, to give you a taste of moving from the conceptual to the technical, consider this: those lines I just mentioned come from finding the minimum of a cost, or loss, function using a technique called gradient descent. All that means is that we use gradient descent to choose the best parameters for a model. The “best parameters” are the ones that minimize that cost function. And here a “model” can be thought of as “a way to acquire experience by learning from data.”
I’ll dig into all of this a bit more in these posts but, as you can see, it’s very easy to summarize what we’re doing in machine learning yet there comes a point where you start running into some complexities.
It’s Not About Explanations
Here’s a quote from the book Probably Approximately Correct: Nature’s Algorithms for Learning and Prospering in a Complex World:
“[Machine learning is] a method for finding patterns in data that are usefully predictive of future events but which do not necessarily provide an explanatory theory.”
The lack of explanatory theory means we’re not really using machine learning to help us understand why something is the case. Rather, we’re just learning what seems to be the case, given the data that we have. And that’s really important because, as you can hopefully intuit from that, there’s still quite a bit of room here for the human.
The predictive part is important there as well. Prediction is nothing more, but also nothing less, than the process of filling in missing information. Of relevance is another quote, this time from the book Prediction Machines: The Simple Economics of Artificial Intelligence:
“Prediction takes information you have, often called ‘data,’ and uses it to generate information you don’t have.”
What to do with that information or how to use it for further research is still very much in the province of humans.
As testers, I hope a few of these points are resonating, particularly in an industry that is suggesting a whole lot of testing will be replaced by artificial intelligence or machine learning algorithms. Instead, at least on the immediate horizon, these tools will support development and testing; they will augment and aid humans, but certainly not replace them.
The Plan of Attack
One goal of this series is that by the end of it, you will understand what it means to construct a very simple neural network and thus practice some deep learning. You will understand the basis of how such networks are trained with data. And you will understand how that work then translates into classification and prediction. For these posts, I mentioned we’ll be using the “hello world” of examples and, currently, that’s something known as the MNIST handwritten digits data set.
I will have a Python-based example in this series. I would recommend coding along with me. I’ll provide all source code and we’ll build everything in small increments. You certainly don’t need to be a Python expert to follow along. If you are going to code along with me, make sure you have Python 3 installed and, if you’re on Windows, do make sure you have a 64-bit version of Python. Anaconda, Enthought Canopy or other such distributions will work just fine as well.
All that said, this first post is going to be about providing some necessary context. First, I’ll cover some background then we’ll close out by making sure you have the tools you need. The first part of the background to cover is what kind of learning we’re actually doing here, which is going to be of the “supervised” variety.
Supervised Learning
First, let’s get a high-level visual of a context for supervised learning:

As you can see, supervised learning tends to be broken down into two tasks: classification and regression. I’m going to be focusing mainly on the classification aspect in this series, but prediction (regression) will play a part. There are two concepts in the above visual that I need to provide clarity around: examples and targets. To do that, let’s talk about attributes.
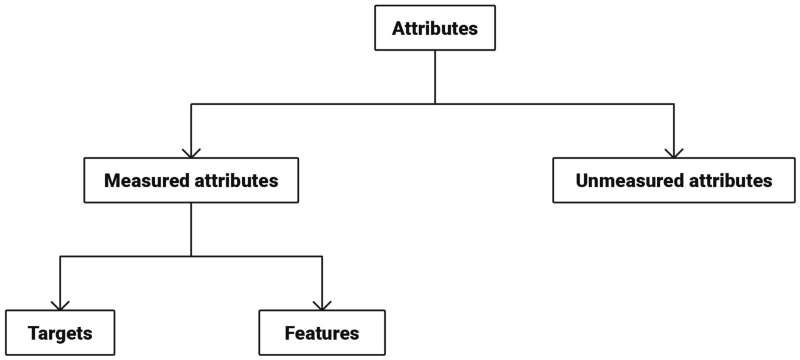
An attribute is something that characterizes anything we want to study. Some attributes we want to measure, others we don’t. Measured attributes, as shown above, are either targets or features. Let’s break those down.
- A target is an attribute that we care about and that we want to predict. You can think of the target as an outcome measurement or output variable.
- A feature is an attribute that is (potentially) related to the target. You can think of a feature as an input variable.
Clearly I’m taking you on a terminology tour and I’m going to continue on that path for a bit. While I’m going to throw a series of terms at you here, I think you’ll find these largely intuitive.
- Data is any collection of measured attribute values.
- A collection of such measurements taken at any one time or in any one situation is a data point which is also called an observation.
- An example (also called a sample) is a data point that has been collected to provide to a machine learning system in an effort to solve a machine learning problem.
- A data set is a collection of examples.
- An example is said to be labeled when it includes a target value and is said to be unlabeled when the target value is absent.
If you have a statistics background, consider how there is a difference between population and samples. In this context, the observations would be the population. The examples are the samples. They are the subset of the observations that you are planning to use.
With that terminology in place, it should now make sense when I say that supervised learning uses data sets with labeled examples. The fact that the examples are labeled is what makes this learning supervised. The idea being that a teacher or supervisor has attached these labels to help the machine learning out.
Machine Learning Workflow
Machine learning is based on the premise that there are relationships between features and targets and that these relationships repeat in a predictable manner. If the machine learning algorithm — often called a learner in this context — can find that relationship, then presumably it can make predictions based upon it.
Given that, a high-level workflow of machine learning could thus be framed as:
- Collecting relevant data.
- Recognizing patterns.
- Generating predictions.
In the next post, I’ll refine that workflow into a life cycle of activities but the above is a good starting point.
Classification
Looking back at the breakdown of supervised learning tasks, I mentioned classification and regression. And earlier I talked about thinking of machine learning as drawing lines. Well, now I can expand a bit and say that drawing lines to separate data is referred to as classification. Drawing lines to describe data is referred to as regression.
In a classification task, the target we are trying to predict is discrete, meaning that it can take on one of a certain number of finite values. Another way to say it is that the value belongs to one, and only one, of a certain number of classes. In machine learning a category in a classification problem is called a class.
When the target is one of two — and only two — possible discrete outcomes, the task of predicting the correct class is called binary classification. Otherwise you’re talking about multiclass classification. Simplistically speaking, think of a binary classification task as being one where your output will either be 0 or 1 and nothing else. A multiclass classification would be one where your output could be any number between, say, 0 and 9.
Using Data to Classify and Predict
The basic idea we’re building up to is no more complicated than this: in supervised learning, an algorithm learns a pattern for making decisions from training data. One of the better diagrams of this I’ve seen is this one:

The whole idea of this kind of learning is that, as the visual shows, we have training data that provides some examples to a problem. We also have outcomes as part of that data, associated with the examples. What specifically is being trained here, though? This is something usually referred to as a model.
I’ll come back to what a “model” actually refers to in the next post but remember that earlier I said a model could be thought as “a way to acquire experience by learning from data.” With the added context I’ve given you, you can think of the model as a way of making decisions based on data.
In our case, the specific decisions we’ll be talking about are classifications. So think of the model as a classifier: acquiring experience with enough data that it becomes possible to make decisions about how to accurately classify something.
Going back to the visual, we have data that has outcomes provided for it. And, to be sure, classification is really easy when you’re given the outcome. It’s like being given the answers to a test in school! However, think about how we train children to learn subjects. We don’t just give them the answers to tests. But we do give them answers (outcomes; targets) to practice problems. We expect the children to learn from those practice problems, where the answers are provided, and then to be able to provide their own answers for non-practice (test) problems.
That’s literally what we’re doing in machine learning as well. Our model trains on some outcome labeled data so that the model will be able to classify the outcome of test data. The test data is data that, like the training data, also has the outcome recorded, but unlike the training data, has not been seen by the model.
The power of machine learning models comes from their ability to learn some representation in the training data and how to best relate that representation to the outcome. The outcome is ultimately what you want the model to classify or predict, depending on the kind of problem you’re dealing with.
Does This Really Involve Learning?
Are machines actually learning? There are a lot of philosophical debates about whether machine learning is appropriately named and those debates often swirl around what people think “learning” means to a human compared to what our machines are doing in this context. I don’t plan to wade into those debates here. But this is an example of semantics that matter and thus it is good to consider what we mean by learning in this context.
Learning, in the context of machine learning, basically describes an automatic search process for better representations. At the core of all machine learning algorithms is a means of finding transformation mechanisms that turn data into more-useful representations for a given task.
That, fundamentally, is what machine learning is: searching for useful representations of some input data.
It’s About Finding Useful Representations
Let’s expand that a bit. Machine learning is about searching for useful representations of some input data within a predefined space of possibilities, using guidance from some sort of feedback signal that tells us how good or bad our representations are. This (relatively) simple idea allows for solving a sometimes surprisingly broad range of intellectual tasks, from speech recognition to cars that drive themselves.
Deep learning is a specific subfield of machine learning. But essentially all that means is that deep learning is a new way of learning representations from data that puts an emphasis on learning successive layers of increasingly meaningful representations. In deep learning, these layered representations are, more often than not, learned via models called neural networks.
Okay, But Is It Learning?
Ada Lovelace, back in 1843, remarked on the invention of Babbage’s Analytical Engine as such:
“The Analytical Engine has no pretensions whatever to originate anything. It can do whatever we know how to order it to perform. … Its province is to assist us in making available what we’re already acquainted with.”
Taking that context, machine learning considers a specific question: could a machine go beyond “what we know how to order it to perform” and learn on its own how to perform a specified task? So, for example, rather than programmers crafting some rules for processing data, the machine would automatically learn these rules by looking at the data.
That is the context of learning that matters for these posts. That kind of learning is part of what humans do; but it’s not all that humans do when learning. So while it’s true that machine learning isn’t a facsimile of human learning, it’s not inaccurate to say that it’s a restricted form of learning.
The Quality of Solving Problems
Consider this quote from the book The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World:
“At its core, machine learning is about prediction: predicting what we want, the results of our actions, how to achieve our goals, how the world will change. These predictions are generally trustworthy but they are limited to what we can systematically observe and tractably model.”
In these posts we will be systematically observing a series of scanned handwritten digits. The model we are looking for is made tractable if we can have our model take the digits that a human wrote and learn what the digit actually is, given the vagaries of human writing.
Let’s also consider an interesting point about testing and quality in this context. Computing science has traditionally been all about reasoning deterministically. Machine learning tends to be about reasoning statistically. If a given algorithm is, say, 87% accurate, that doesn’t necessarily mean that the algorithm has bugs that are preventing it from getting to 100%. That 87% may be the best we can do and, in fact, that could be more than good enough to be useful.
This is definitely something to keep in mind as you think about testing in the context of machine learning and what the barometer for quality is.
Our Tooling
I mentioned earlier we would be using Python 3 as our implementation language. Within that context, I’m going to use a library called Keras for much of our work. Keras is a model-level library and, as such, it provides high-level building blocks for developing deep learning models, one of which is the neural network.
Keras is also an abstraction layer for various deep learning libraries, the most popular of which are Theano and TensorFlow. The abstraction makes working with deep learning a lot easier and simplifies the creation of neural networks. For example, by using Keras you don’t have to deal with low-level operations such as tensor manipulation and differentiation. On the other hand, that’s also a danger. Abstraction can hide from you what’s actually going on and that can make reasoning about what’s actually going on quite a bit harder.
Another reason I’m using Keras is because it has a nice datasets library, one of which is a built-in MNIST database of handwritten digits. So the benefit here is that with the code I provide you, the dataset will be downloaded automatically if you didn’t already have it.
Get Your Tools in Place
Hopefully you have Python 3 at this point.
Modeling Library
To follow along, make sure you get the Keras library and NumPy library, as such:
pip install keras
Installing Keras will also get you NumPy.
Do note that, depending on your operating system and how you installed Python, you might have to use pip3 instead of pip and you might need to use “sudo” for those commands.
Tensor Library
Even though Keras can be a front-end for TensorFlow, it won’t install TensorFlow as a dependency. TensorFlow is just one of the possible backends for Keras and it is the one Keras will use by default if it’s present. So let’s make sure we have TensorFlow available:
pip install tensorflow
I can’t stress enough: if these tools are new to you, don’t worry. Basically TensorFlow will be our deep learning computation engine and Keras is a front-end for that engine. Keras provides a higher level API for interfacing with TensorFlow, thus removing some of the complexity.
Running Computations
I’m going to dive into the weeds for a second here, so bear with me.
One of the nice things is that via TensorFlow, Keras is able to run on both CPUs and GPUs. This detail won’t matter much to you for these posts but if you get into computation-heavy problems, even multi-core CPUs won’t help you. That’s where GPUs come in. Many cloud-based solutions, like Amazon’s EC2 Deep Learning AMI or the Google Compute Cloud are designed to let you leverage GPUs at scale. But you can also use your own GPU locally.
You can install TensorFlow without GPU support (pip install tensorflow) or with it (pip install tensorflow-gpu). TensorFlow wraps a low-level C++ library for tensor operations called Eigen and, if one is available, will rely on a Basic Linear Algebra Subprogram (BLAS). BLAS is the low–level part of your system that’s responsible for efficiently performing numerical linear algebra. This will let you run fast tensor operations on your CPU. Having a BLAS installed can be helpful. Examples here are OpenBLAS for Linux or the native Accelerate Framework for Mac. There’s also Intel’s Math Kernel Library (MKL).
If running on a GPU, TensorFlow wraps cuDNN which is an NVIDIA library of highly optimized primitives for deep learning. This library, in turn, requires CUDA, which is a set of drivers for your GPU that allows it to run a low-level programming language for parallel computing. The combination of the drivers and the library can very significantly increase the training speed of your models.
It may also be relevant to note that there is work being done on TPUs (Tensor Processing Units) that have been specialized and optimized to run tensor operations.
I said I was going into the weeds and I bet you agree. Do know that I’m not assuming knowledge of any of these libraries or technologies. Okay, then why did I bother bringing all that up? Well, in part just as a matter of interest so you know what you’re installing. But also because from a testing standpoint, the above details matter!
The quality of these solutions can depend on the architecture on which they are running. Also, you presumably want your tests to finish sometime before the heat death of the universe. Some models and their data get incredibly large and this means you need to take advantage of scaling in order to have any hope of getting results you can reason about.
Continuing on, there is a group of tools often referred to as the Python scientific suite. That would be Numpy, SciPy, Matplotlib. We already got Numpy so we’re good there.
Plotting Library
We’ll definitely do some visualizing of our data, so let’s make sure you have a library that make this a bit easier than it otherwise would be:
pip install matplotlib
Scientific Library
Regarding SciPy, I don’t think we’ll need this too much but there is at least one point where I see us needing an optimized mathematical engine, which is what SciPy provides. So make sure you get that as well:
pip install scipy
Something else you may want to do is draw visualizations in the form of graphs. For that Graphviz is a tool well worth becoming acquianted with. It basically lets you draw graphs using a graph description language called DOT. You can check out its downloads. On Mac, you can just install with Homebrew. You can build from source on Linux and there are Windows installers available.
There is a Python package called pydot that provides an interface to the DOT language. So let’s get that as well:
pip install pydot
All of the above libraries should be all you need to follow along.
What We Accomplished
This post has been heavy on concepts and terminology. If you feel a little adrift, that’s okay. I’m not assuming any prior knowledge of too much here. We’ll get into all of this as we move along. Just keep in mind that knowing what you don’t know is the first step to figuring out what you need to know … in order to know the things you want to know. That is an accomplishment.
I think the stage is well-set at this point for our journey. We got the context that we’ll be operating within. We have some understanding of the specific domain we’ll be working with. And we have the tooling we’ll use to explore both the context and the domain.
Join me in the next post as we continue our journey!

This is awesome and really well detailed! Your series is a wonderful addition to my crash course in data science and machine learning.
Coming from one of the smartest people I have had the pleasure to work with, this is high praise for me indeed and I sincerely appreciate it.