Here we’ll pick up from the first post and get to work with our machine learning, specifically focusing on getting a data set, exploring it a bit, and then doing some processing on the data to get it into a format that would be usable for a neural network algorithm.
Our Data Context
I mentioned in the first post that we would be using the MNIST handwritten digits database. Let’s get a little context for this, starting with what it is. Back in the 1980s, the National Institute of Standards and Technology (NIST) created what they called a modified dataset (called MNIST) containing grayscale images of handwritten digits.
An entry level task into machine learning is the use of this data set as a classification exercise. The goal of the exercise is to train an algorithm to accurately recognize handwritten digits. The fact that the digits are handwritten means a lot of variation in terms of how the numbers are represented. Here are some examples from the data set:

The data set is made up of 60,000 training images and 10,000 test images, where each image is 28 × 28 pixels.
The training images are scanned handwriting samples from a population of 250 people. Half of this group was made up of United States Census Bureau employees and the other half were high school students. The test images were taken from a different population of 250 people than the original training data, but still with an equal group split between United States Census Bureau employees and high school students.
Using the terminology introduced in the first post, the data set is said to contain ten categories, also called classes. Specifically, those classes are the digits 0 through 9. Each image is a data point and each data point is called a sample.
Bringing the above details together with achieving the previously stated goal means that you build a model that will learn from the training images. The model tries to understand the patterns that lead a given category of image (of 9) being given a certain label (of “9”).

The model is essentially learning to associate images and labels. Then you can test how well your model learned by having it run against the test images. Here the model should attempt to predict what the label will be for a given image. It should be able to do this because it will have understood how to classify those images.
Again, with the terminology from the first post in mind, the labels are the outcomes or the targets. We want our model to “hit the target”, meaning to accurately classify an image as being associated with a label.
Does This Really Involve Learning?
In the first post, I had a section titled the same as this one and I answered that at a bit of a high-level. I think it’s important to frame that question again but this time leading into the specific work we’re going to be doing.
Learning, in the context of machine learning, describes a process for finding better representations of data. A central problem of machine learning is to meaningfully transform data, which basically just means to learn useful representations of whatever input data we have. We measure “usefulness” by how much closer to an expected output those representations get us.
What this means practically is that we need a way to determine the distance between a model’s actual output and its expected output. How do we do that? Essentially, we provide a feedback signal. A feedback signal to a model will tell it if the distance between the actual and the expected is increasing or decreasing.
But what’s the model supposed to do with that information? The model will then have to make adjustments accordingly. Those adjustments could be described as the process of learning. The adjustments that lead to decreasing the distance between the actual output and the expected output is another way of describing how data is transformed into different and more useful representations.
Thus we can say that machine learning is basically searching for useful representations of some input data within a predefined hypothesis space of possibilities, using guidance from a feedback signal. This machine learning becomes “deep learning” when you have algorithms that learn successive layers of increasingly meaningful representations.
These are all bits that I mentioned in the first post. I hope this repetition here helps to reinforce these ideas.
Representations of Data
Let’s consider what the above process might look like in the context of our MNIST data:

Here we have a simple transformation of an MNIST digit. What happens between the input and the output — what happens inside the layers — in order to allow the image 4 to be associated with the label “4” is where learning occurs. We can even further expand that view:
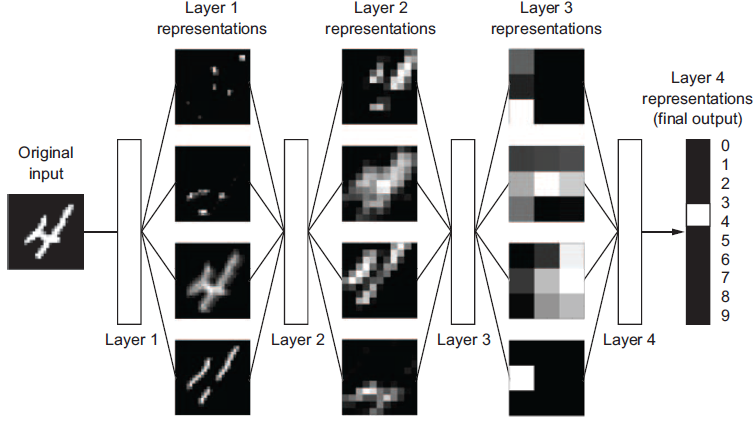
The model, made up of layers, will transform the digit image into representations that allow the algorithm to learn the features that associate 4 with “4”.
A key point to understand is that deep neural networks with many hidden layers can sequentially learn more complex features from any input image. For the relatively simple MNIST data set, the image features don’t get that complex. But let’s think about how this scales up.
Consider trying to recognize whether an animal is in an image. The first hidden layer might only learn local edge patterns that ultimately frame all objects in the image. Then, each subsequent layer might learn more complex representations. Maybe the next layer learns gradients. Then the next one learns shading. Then the next one uses the output of those two previous layers to learn perspective. Finally, the last layer, the output layer, can generally classify the image as having something in it.
Processing of Data
Overall a deep learning model is basically an engine made up of different layers that we can think of as data processing units. Each of those units contains data filters. These units are stacked up one after the other or one on top of the other, depending on the visualization you prefer. What’s important is that the model passes inputs (data) through the stack of layers.
That’s basically a neural network. Each data processing unit is a layer that takes in some data, performs some filtering on it, and extracts some representation out of the data, and then outputs that representation.
The “model” in all this is a bit of a vague term. The neural network itself is sometimes called the model. However, I find it’s better to recognize that a neural network is really an algorithm. The model is that algorithm plus the representations that are learned as data is fed to the algorithm.
Another way to frame this is that you can think of the network or model as a big math equation. We put data in, some calculations occur, and then some data pops out. If that sounds to you like how mathematical equations work, you now have a path from the intution of what machine learning is to how it actually works.
Mathematics Applied to Data
In fact, let’s dig in just a tiny bit to the mathematical underpinnings here.
I keep talking about “filtering” or “extracting” or “transforming.” What’s actually doing all that? Generally speaking, that’s a bunch of math operating behind the scenes.
Machine learning is fundamentally a mathematical framework for learning representations from data. To put a little meat on that statement, all transformations — all aspects of filtering data into representations — that are learned by deep neural networks can be reduced to a handful of tensor operations applied to tensors of numeric data.
These deep learning models that we’re talking about only work with numeric tensors. I’ll revisit tensors later so don’t worry too much about them right now. In fact, with the libraries we’ll be using you technically don’t have to worry about them at all. But, as you might guess, TensorFlow is named for these tensors. It’s the underlying library that performs tensor operations and the “flow” part of TensorFlow refers to those tensors flowing through layers.
Conceptualizing the Math/Data Relationship
Depending on your experiences with math, all of that can seem a bit intimidating but there’s a fantastic description of this in the book Deep Learning with Python that I’ll use here. In that book, François Chollet puts this tensor stuff in context:
“Neural networks consist entirely of chains of tensor operations and all of these tensor operations are just geometric transformations of the input data. It follows that you can interpret a neural network as a very complex geometric transformation in a high-dimensional space, implemented via a long series of simple steps.”
Chollet then asks us to consider this visualization:

I like that visualization because, conceptually, a neural network is searching for a transformation of the paper ball that would uncrumple it.
But now imagine two sheets of paper, each differently colored or perhaps with different writing on them. Then crumple up both of them together. The neural network can apply that same uncrumpling process used for the single crumpled paper to make the two classes of paper separable again. As Chollet states:
“Uncrumpling paper balls is what machine learning is about: finding neat representations for complex, highly folded data manifolds. [Deep learning] takes the approach of incrementally decomposing a complicated geometric transformation into a long chain of elementary ones, which is pretty much the strategy a human would follow to uncrumple a paper ball.”
The term “manifold” there might have thrown you a bit. Let’s talk about this.
From Numbers to Geometry
Imagine holding an uncrumpled piece of paper in your hand. That paper represents two-dimensional data in three-dimensional space. That’s a pretty rough explanation so let’s take another example that we’re all familiar with. Earth is a two-dimensional manifold or a surface. What that means is that it’s a space that looks locally like a flat plane … but it may have a different global structure.
And we know that to be the case. While the Earth looks locally flat, globally it’s a sphere. Or, if striving for complete accuracy, an oblate spheroid. A key point here is that the Earth could also have have been something other than a sphere. It could have been a torus, for example. But that wouldn’t change the fact that the surface would be locally flat any point. So we have a two-dimensional manifold, which would be like the “highly folded data manifold” mentioned in the above quote.
One more quick point here: a manifold captures precisely the local flatness in any dimensions. The reason that’s important is because it let’s us talk about the rate of change of something on that manifold. This is essentially how we can perform activities like differentiation, which does factor into machine learning.
This movement from numbers to linear algebra to geometry is actually really important. It will take me into the next post to cover that. Remember that Douglas Adams quote from the first post? The above might have been another such moment for you. Don’t panic! We’ll get more into these topics.
Visualizing the Operations
Now let’s take some of what I said above and workflow it out, so to speak. I’ll respectfully borrow a few more images from Chollet’s work to visualize that process:

If I’ve presented things well so far, that visual workflow should make sense. We have inputs, here labeled X, and we have outputs, here labeled Y. The outputs are predictions or classifications. Our expected output is Y. The trick is we want the neural network to come to that conclusion by passing the input (X) into its layers and doing some transformations on X such that it’s actual output matches the expected output.
The transformations that are implemented by a given layer are parameterized, or modulated, by the weights (w) of that layer. Remember those adjustments I mentioned earlier? What this visual shows is a refinement to that idea.
Learning means the neural network finds a set of values for the weights in each layer. It’s the actual weights that are being adjusted. But what actually is a weight? In this context, just think of the weight as how much value you give to certain parameters that are being operated on in the layer.
A neural network will adjust these weights based on the distance between the expected output and the actual output. Let’s add to our visualization here:

To control the output of a neural network, you need to be able to measure how far the actual output is from what you expected. This is the job of something called the loss (or cost) function of the network. The loss function takes the predictions of the network (what the network did output) and the true target (what you wanted the network to output) and computes a distance score, capturing how well the network has done on a specific sample of data.
This is getting us to that feedback signal I mentioned earlier. Let’s expand our visualization once more:

The fundamental trick in machine learning is to use this computed loss score as the feedback signal to adjust the value of the weights. But adjust them by how much? Well, that’s part of what’s being learned.
Ultimately the goal is to adjust the weights in a direction that will lower the loss score for the current sample. This adjustment is the job of something called an optimizer, which implements what’s called a backpropagation algorithm. Backpropagation is pretty much the central algorithm in much of machine learning and it really just means taking information at the end of the process and propagating it back to a point earlier in the process.
Quick Math Side Trip
If you are familiar with linear algebra — and I mentioned it above to get you thinking about it — you’ll note here that we have y, x, and w as aspects of our model. Can you think of any equation you learned that has those as part of a single calculation aspect? It might help if I introduced another parameter called b.
Any ideas? How about this:
f(x) = xw + b
We have a function of x such that x multiplied by w and added to b gives us a line. Remember about machine learning being fundamentally about drawing lines? Let’s replace the f(x) as such:
y = xw + b
Well, that’s just a linear equation, isn’t it? Indeed so!
In linear algebra terms, x is your input, w is your coefficient and b is called the intercept. The only difference in machine learning is that we call w the weight and b the bias. I’ll come back to this. I find a gradual introduction of math interspersed if often better than just a total focus on it in one shot.
Learn By Training
A core idea here is that the model is trained. Training is how experience is acquired. And the acquisition of experience is how learning is achieved, assuming that the experience can be extrapolated from.
A simplified, but not inaccurate, view of how training works is that initially the weights of the network are assigned random values. This would mean the model implements a series of random transformations. As you can imagine, from that kind of starting point, the output of the model will likely be far from what it should ideally be. This would imply that the loss score is going to be quite high.
But with every sample the model processes, the weights are adjusted a little in the correct direction. “Correct” here is determined by seeing the loss score decrease. The goal is ultimately finding weight values that minimize the loss function as much as possible. A model with a minimal loss is one for which the actual outputs are as close as they can be to the targets, which are the expected outputs.
Neural Network Life Cycle
How do we make those concepts and visualizations operational? How do we turn those ideas into working code that we can observe and test? Even more to the point, how does any of this go from theory to practice?
There is a life cycle, for lack of a better term, to a neural network model. The life cycle is essentially this:
- Gather and Prepare Data
- Define the Model
- Compile the Model
- Fit the Model
- Evaluate the Model
- Generate Predictions from the Model
How this is actually implemented in various tool libraries will differ but they all should be following this life cycle.
The first step of gathering and preparation is, of course, extremely important because it’s this data that we’re going to feed to the network we create. In our case, ultimately we’re going to use some pre-existing data that was encoded for us and thus was preprocessed. But I’ll also do some processing with you, reshaping and scaling the data, just so you can see how it works.
Before we get to that, I’ll use the remainder of this post to how you how to do a bit of initial data gathering. You’ve been patient with a lot of theory; so let’s get to some practice.
Processing our Data
I described the MNIST data set earlier. This data set is actually part of the Keras set of provided data sets and ultimately that is what we’re going to use. But I did want to take a little time and show you what it would mean to be given data in a raw encoded format. Here I want to show you a bit of how that data gets to the point where it’s usable and I’m doing this mainly because many tutorials out there don’t do this.
First a little history for you: the first successful practical application of neural nets came in 1989 from Bell Labs. A researcher named Yann LeCun combined the the existing ideas of convolutional neural networks and backpropagation and to showcase how this worked he applied the resulting combination to the problem of classifying handwritten digits.
That context will make you understand why I want you to check out the raw encoded data set from Yann LeCun’s website:
http://yann.lecun.com/exdb/mnist/
There are four files at the above site. You can download those and then uncompress them. This raw data has already been processed to an extent. As the site itself says:
“The digits have been size-normalized and centered in a fixed-size image.”
Yet what you will end up with is four binary files which isn’t entirely helpful to us for machine learning purposes. What we can do is run a processing program of our own creation to get that data into a format that ultimately could be passed to a neural network. Create a script called process.py in the same location as your uncompressed MNIST files. Add the following logic:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
def process(image_file, label_file, output_file, samples): input_images = open(image_file, "rb") input_labels = open(label_file, "rb") output = open(output_file, "w") input_images.read(16) input_labels.read(8) images = [] for i in range(samples): image = [ord(input_labels.read(1))] for j in range(28*28): image.append(ord(input_images.read(1))) images.append(image) for image in images: output.write(",".join(str(pixel) for pixel in image) + "\n") input_images.close() input_labels.close() output.close() process("train-images.idx3-ubyte", "train-labels.idx1-ubyte", "mnist-train-data.csv", 60000) process("t10k-images.idx3-ubyte", "t10k-labels.idx1-ubyte", "mnist-test-data.csv", 10000) |
Run the script, which should only take a minute or two at most to run. That will get you two files: mnist-train-data.csv and mnist-test-data.csv. Keep in mind what I said earlier: “the data set is made up of 60,000 training images and 10,000 test images that are of size 28 × 28 pixels.” Given that, some of the numbers in that script may make some sense.
The format of these csv files is a series of rows and columns. The first column will be the label, which means what number is encoded for that row. The remaining columns can be thought of as pixel11, pixel12, and so on, where the general format is pixelij meaning the entry for that cell is the pixel in the ith row and jth column.
This process is important. If you can get your data into what amounts to a spreadsheet-readable format, you know that it can be fed into a neural network.
There are a few bits of nomenclature I should clarify here. While I’ve talked about rows and columns, when you get into machine learning the rows are called observations or samples. The columns are referred to as features. It’s also more often the case that the target variable or expected output is at the end, meaning the last column, rather than the first.
Checking Our Data
Now let’s do a little experimentation to see what we got. Create a new script called mnist_data.py. In that script, let’s bring in some of the libraries we’ll need:
|
1 2 |
import numpy as np import matplotlib.pyplot as plt |
Now let’s open one of those data files:
|
1 2 3 |
input_file = open("mnist-train-data.csv", "r") input_data = input_file.readlines() input_file.close() |
Now we can check the count of samples and get a look at one of the samples:
|
1 2 |
print(len(input_data)) print(input_data[17]) |
This gives you a count of 60,000 which is how many training images are in the data set. Then you get an idea of what one sample in that data set looks like.
The first number is ‘8’ which is the label. The rest of the 784 numbers are the color values for the pixels that make up the image. If you glance at the numbers you can tell these color values seem to range between 0 and 255.
Essentially, what our processing of the data has done is something like this:

Basically you have an array from the data that is serving as a representation:

Let’s plot out the array of numbers to see what we get. To do that, we need to convert that list of comma separated numbers into a suitable array.
|
1 2 3 4 5 |
all_values = input_data[17].split(',') image_array = np.asfarray(all_values[1:]).reshape((28, 28)) plt.imshow(image_array, cmap='gray', interpolation='None') plt.show() |
I don’t want to make this series of posts too much about processing data but I do want to give you some idea of what’s happening here.
The above logic first splits the string of comma separated values into individual values, using the comma as the delimiter. The first value of the resulting data is ignored because it’s the label. Thus the logic takes the remaining list of 784 values and turns those values into an array which has a shape of 28 rows by 28 columns. Specifically, the reshape((28, 28)) part is what makes sure the list of numbers is wrapped around every 28 elements to make a square matrix of 28 by 28.
Finally, the logic plots the resulting array. This is done using a grayscale color palette (cmap='gray') to better show the handwritten characters. The plotting function is told not to try blending the colors (interpolation='None'). Blending the colors would make the plot look smoother but it’s hardly something we’re concerned about.
Then we show the image, which, if you run the script, you can see is an 8 and that does match the label (“8”) that was provided for that data sample.
Why am I doing all this? Well, the main thing to note here is that we reshaped the data into a 28 × 28 array. That will be something we revisit later but the short story is that you need to make sure your data is in a format that a neural network can do something with.
Also, going through this exercise has proved to you some of the assertions I made about this data set, namely that it is made up of a certain number (60,000 samples) and those samples are handwritten digits that are encoded as numbers.
Scale Our Data
Just to show how we can do a things with our data to make it easier to work with, let’s rescale the input pixel values from the larger range of 0 to 255 to the much smaller range of 0 to 1. This can done fairly simply by dividing the raw inputs by 255:
|
1 2 3 4 5 |
scaled_input = (np.asfarray(all_values[1:]) / 255.0) print(scaled_input.tolist()) rounded_list = ['%.3f' % item for item in scaled_input.tolist()] print(rounded_list) |
That output will show you the modified numbers and show you how they are scaled. This may give you a bit of concern, however. Does doing this cause us to lose any details about the image? Well, let’s generate another plot based on this scaled input and see.
|
1 2 3 |
image_array = scaled_input.reshape((28, 28)) plt.imshow(image_array, cmap='gray', interpolation='None') plt.show() |
You should see the same image generated as before. Scaling or normalizing data is a very important part of machine learning and it’s good to see that doing so causes no loss of fidelity to what we’re dealing with.
Understanding the Data Set
What you can see is that entries in this dataset might look something like this:

You might notice something interesting with the image I’m showing you there. In that one, the background is white while the foreground is black. However, in the plots you generated it was the reverse. Don’t worry about that but if you noticed it, that’s good.
As stated before, each image has 28 × 28 pixels. This means you can think of each image data point as a 28 × 28 array, which I was able to show you above. But what you can see is that this is an array of numbers describing how dark each pixel is in the image.
Let’s even take it one step further. That array can be flattened into a 28 × 28, or 784, dimensional vector. This means that the data set as a whole is a collection of 784-dimensional vectors. You saw that with our data set above in terms of the csv files: we had a set of rows (samples), each of which was made up of 784 columns (features).
But now think of such an image where a number from 0 to 9 is part of that image, as shown in the visuals above. The vectors making up parts of the actual digit will be just a few of the total possible 784 possible vectors. In any given point in one of the images, each pixel is going to be black, white or some shade of gray. The result is that random points will statistically tend to look like noise:

What to take from all this is that the MNIST data points — the actual digits — are not the 784-dimensional space; they are rather embedded in such a space. The portion of that dimensional space that corresponds to anything about the digit is a subset. In machine learning, it’s common to refer to a “hypothesis space” which means a space of possibilities. Here that space has a dimension of 784.
One of the better ways I’ve seen to visualize this was provided by Christopher Olah. He invites us to think of an “MNIST cube” wherein the data points are all part of a 784-dimensional cube.
![]()
A three-dimensional cube would represent, say, height, width and depth. So what do all the dimensions of this MNIST cube refer to? Each dimension, in that visualization, corresponds to a particular pixel. Olah says:
“On one side of the dimension, there are images where that pixel is white. On the other side of the dimension, there are images where it is black. In between, there are images where it is gray.”
These values will be indicating foreground and background colors. And here is where that visual discrepancy above will become important. I’ve shown you cases where the background is black and the foreground (the digit) is white. I’ve also shown you cases where the background is white and the foreground is black. Which way it is in your data set doesn’t really matter, but you knowing which way it is does matter because your machine learning algorithm will be making its predictions based upon a distinction between foreground and background.
Stating with Keras
I want to take you through one more exercise here, which will set us up for next coding activities. We’re actually going to throw away everything we built in this post. You may question if I’ve just wasted your time but I’ll argue that what we did in this post was useful for learning purposes. The good news is that we’re going to make things easier on ourselves. We’re going to be using Keras for the rest of these posts, so let’s get started with that.
First, let’s create a script and set up some libraries that we’re going to want to use. Call the script mnist.py and then add the following to it:
|
1 2 3 4 |
import numpy as np import matplotlib.pyplot as plt from keras.datasets import mnist |
Here we’re getting numpy, matplotlib, and keras in place. As mentioned, a version of the MNIST dataset comes preloaded in Keras. This data is made available via four arrays: training images, training labels, test images and test labels. So let’s make sure we load that data:
|
1 |
(train_images, train_labels), (test_images, test_labels) = mnist.load_data() |
If this is your first time using the mnist dataset from Keras, when you run this script, that data set will be downloaded and you’ll see something like this:
Downloading data from https://s3.amazonaws.com/img-datasets/mnist.npz 11493376/11490434 [==============================] - 2s 0us/step
The Full Data Set
Let’s do a quick little exercise here just to show you how to generate information about the full data set. As a note, you might not want to do this if you’re running on Windows. Mac and Linux users will have no issues; Windows sometimes does.
It’s all fine and good to look at individual samples as we did with the previous example — and we’ll have cause to do that again with the Keras data set — but let’s also see how we can get the full data set. I’m not really going to explain any of this too much because it’s a bit of a side road. For now, add the following to your script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import math from scipy.misc import imsave for (data, name) in [(train_images, "train"), (test_images, "test")]: grid = math.ceil(math.sqrt(data.shape[0])) width = grid * data.shape[1] height = grid * data.shape[2] images = np.empty([width, height]) for index in range(data.shape[0]): i_offset = (index % grid) * data.shape[1] j_offset = (index // grid) * data.shape[2] for i in range(data.shape[1]): for j in range(data.shape[2]): images[i_offset + i, j_offset + j] = data[index, i, j] imsave(name + ".png", images) |
Go ahead and run that; this can take a little bit of time to run. On a Mac or Linux it can take anywhere from one to three minutes. On Windows, it’s quite likely it will not finish in any sort of reasonable time frame.
There’s a lot going on here and I don’t want to get too into these weeds. Just know that the data.shape statements refer to the dimensionality of the data, which I’ll cover more in a future post. Basically, train_images.shape[0] would be 60000 while test_images.shape[0] would be 10000. For both training and testing, .shape[1] and .shape[2] would be 28.
Essentially what this is doing is creating two files (train.png and test.png) and these files will contain a representation of the entire data set. That’s why it takes this script a bit of time to execute. Why do this? Because it does allow you to understand the data set in its entirety. By looking over those generated images, you can get a feel for how varying the handwritten digits are.
If you’re running on Windows, you’ll likely see your image files very slowly building up. That was another reason I brought this up. If you are in a Windows environment, some things either won’t work well or won’t work at all when dealing with machine learning and artificial intelligence. For my posts, however, with the exception of the above, everything is operating system agnostic.
Anyway, that’s all I want to do for now. This gives us the start of the script that we’ll be using for the rest of the posts in this series. But do note that the data set provided by and downloaded with Keras is essentially the same kind of data set that you and I looked at in this post. I wanted to take you through this post so that you understand something about how that data was constructed.
What We Accomplished
We did a pretty deep dive into what makes up the data that we are going to be feeding to our neural network. We also considered a neural network life cycle, the first part of which is gathering and processing your data which we focused on in this post. You were able to explore the data a bit and get a feel for how we manipulate that data (reshaping, scaling) in order to make our lives easier.
In the next post, we’re going to step back from the code again for a bit and dive a little into the math.

Hi Jeff,
these posts are fantastic, great job!
I have an issue with the first script on this post. Visual Code told me that:
when I try to run it, the terminal throws:
both the decompressed files and the process.py are in the same folder
Thanks in advance for your help
The Pylint warning that Visual Code is showing is accurate as I’m not actually using the i and the j variables. Those were just to set up a loop that would read the input matrices. I could clean that up a bit.
The problem is definitely with the file being found. I just ran this script on Windows and on a Mac with the decompressed files and had no issues. I know you said the decompressed files were in the same directory but just double checking: do you actually see the file train-images.idx3-ubyte in that directory?
I know you probably checked that. I’m just double-checking because I’m struggling to see what the issue is. The error is unambiguous: it can’t find the file.
I might be missing something very obvious that I did wrong but I’m not sure what at a glance so I just want to make sure you certainly see that particular file in the directory.
Yes, I’ve also just moved both the process.py and the train-images.idx3-ubyte to another folder and same issue.
Just in case, I also tried running another python script (one that prints hello world) and worked fine.
I will check with one of my developers at work tomorrow and figure out what I did wrong (I swear I copy/paste your script)
Regards