A couple of years ago I talked about what I considered to be the basis of testing. I very confidently asserted things. Maybe I sounded like an authority. Maybe I sounded like I was presenting a consensus. But did I really talk about the basis or just a basis? And shouldn’t an ethos have been part of that basis?

To kill any suspense at the outset I think what I said back then was relevant and useful but actually probably not as close to the basis as I had hoped.
An Experimentation Basis
What I perhaps should have done is simply focus on experimentation. I say that because when you get right down to it, that is pretty much all that matters.
This has the benefit of being a statement that doesn’t require too much authority since it’s largely a stance that’s hard to argue against and is a very minimum element of consensus that shouldn’t require too much haggling over. Quite literally, by definition, “to test” has a basis in “to experiment.”
I believe this limited — but not limiting! — view of focusing on experimentation as the key aspect of testing creates an explanation that provides an ethos that allows us to encourage those learning the testing craft. Specifically, we can help such people by getting them used to the idea of always asking and answering two questions during their career:
- Am I thinking experimentally?
- Am I acting experimentally?
Being able to answer “yes” to those questions and being able to operationally articulate how the thinking and acting is being done is part of the ethos of testing. In my view, all other nuance within the testing arena — all the discussions that testers want to have with themselves or others — must fall out of this starting point.
As just one example of my own thinking in this regard, in my “Product Management and the Quality Focus”, I said: “treat every release as an experiment and be mindful of what you want to learn.”
But let’s play this out a little and see how it works, shall we?
The Unseen and the Non-Visible
Let’s first head off in what seems like an entirely different direction. While doing some general research, I came across an interesting editorial in The Lancet from 22 February 1896.

The editorial focused on some of the interesting discoveries around light.
It is obvious that we must attach a deeper and much wider meaning to the word light than has hitherto been ordinarily understood.
Replace the word “light” there with “testing” and, right away, you could apply that same thought to our current testing industry within the wider technology industry. But I also think we risk going a little too deep and too wide, thus complicating testing in areas where it really doesn’t need to be. I think testing has, sometimes, been presented as “overcomplicated,” to use the title of Samuel Arbesman’s excellent book.
Sticking with the historical point for a moment, it’s worth noting that until the eighteenth century, no one really had any idea that there might be such a thing as light that couldn’t be detected by human vision. It wasn’t until the nineteenth century that we had any proof at all of such “non-visible light.”
Translate that into quality problems that we can’t directly see or learning better observational methods as software became more complicated and, even more importantly, as humans began to interact with software that became more complicated. In fact, add to all that the complexity of developing all that software in the first place, with increasing layers of abstractions, such as libraries and frameworks and algorithms, not to mention the many vendors we find ourselves relying on.
There is a lot we don’t initially see in our technological industry. Testing is one mechanism that we use to see better. Metaphorically speaking, testing allows us to turn microscopes into telescopes and vice versa. This allows us to see better and thus frame better questions that experiments help us answer. That, in turn, helps create more plausible explanations that serve as the basis for an ethos.
It sounds simple but it rarely is.
Dismissing Illusions
Related to my historical example above, the progress of science in general has been marked by the dismissal of illusions.

There’s lots of examples here. Matter appears to be continuous but it turns out that it’s made of discrete atoms. The Sun appears to go around the Earth but, actually, it’s the other way around. Biological life appears to be massively distinct and yet it turns out to all have derived from relatively few common ancestors.
Illusions. There are many of them. And science worked to dispel them.
Testing, too, is often about removing illusions. Much like in science, we do this by experimenting and, crucially, listening to our experiments when they tell us something interesting. Key to this, of course, is coming up with experiments that stand a good chance of telling us something interesting.
Testing is Experimentation
It’s really crucial to think of testing as experimenting because that is very much what it is.

You can break down the type of experimenting all you want and come up with dozens of terms and sub-categories. That’s all fine. But a key element to get people to understand is quite a bit simpler than that: experimenting relies on investigating something critically.
“Investigating critically” means that any valid criteria must be publicly arguable, repeatable by all experimenters (“objective” in the sense of “observer-independent”), logical, precise, verifiable, and falsifiable. I would also add another category that’s best thought of as “implausification.” I talk a bit about the latter in “Do Testers Understand Testing?”
We drive decisions by learning from experimenting. That means we have to think experimentally. To perform testing — regardless of what your role is — means you think experimentally. And then you act in a way that allows for critical investigation. So you think experimentally and you act experimentally.
Those two phrases are essentially the whole of the testing craft.
And those phrases are easy to say. And most people can do at least very broad interpretations of both of those things. But thinking and acting experimentally is a discipline. And it’s a discipline that not everyone is willing to do. And we currently, in my view, have a wider testing industry that is complicating testing way more than it needs to by a profusion of distinctions and categories and types that hide the above underlying simplicity.

Think of it this way: in no other discipline based on experimentation has there been a need to come up with so many terms to describe experimentation. Yet, in the testing world we seem to feel the need to do that with testing. It’s worth it for testers to consider why that is.
But would it be simpler if we just started with this: at a minimum anyone performing testing has to understand the idea of testable hypotheses, disciplined experiments, and generating and gathering meaningful insights.
A meaningful insight here means that you gain information that is useful in some way towards driving decisions. Meaningful insights are based on demonstrable and empirical observations and thus on evidence where, just as in a legal setting, the probative value outweighs any possible prejudicial value.
Again, all of what I just said is easy to say. Actually doing it can be trickier. That’s why not everyone is a specialist in scientific disciplines, like math or biology or physics. Similarly, while everyone is a tester to some degree, not everyone is a specialist in testing and thus in experimenting.
Framing as Questions
There are questions that are easy to ask before you even get started:
- Does our experiment have a testable hypothesis?
- Can we actually do the experiment?
- How can we be as certain as possible that the results will be reliable?
It’s quite interesting how many testers don’t even really have the basis of the first question in place. And, at least in my experience, the idea of framing a null hypothesis is almost entirely foreign to many testers.
Whether you call your testing “exploratory,” “experiential,” “interactive,” or whatever else is entirely fine. But, at its core, all such testing must have some sort of testable hypothesis. That hypothesis must be operationally specific enough that it can be subject to experiment.
Some good questions you can ask as you are experimenting are:
- How will we know if an experiment is going well?
- How will we know if an experiment is going poorly?
Here’s a hint: if you don’t have testable hypotheses to begin with, knowing whether your experiment is going well or poorly can be nothing more than a guessing game.
A really important question is this one:
- Is there a commitment to abide by the results of our experiments, whatever those results may be?
That one is really important because it situates experiments within a cultural context that may or may not operate counter to an experimental mindset and practice. No matter how much you think and act experimentally, if the collective will is lacking to abide by the results of experiments, it’s at least arguable that there’s no point in doing the experiments.
Ranging Over Ideas…
The final point there, regarding a “collective will,” actually brings together a few points and I’ll ask you to bear with me here for a bit. First, let’s consider this:
The role of the intellectual is not to tell others what they have to do. By what right would he do so? … The work of an intellectual is not to shape others’ political will . . .
This is Michel Foucault and Lawrence Kritzman writing in Politics, Philosophy, Culture: Interviews and Other Writings, 1977-1984, published in 1988. In that quote, I’ll ask you to read “political will” as being defined as the extent of committed support among key decision makers for a particular solution to a particular problem. So it’s a bit of the “collective will” that I mentioned; more generally, we could speak of a “cultural will.” The above quote continues:
[The work of an intellectual] is, through the analysis that he carries out in his field, to question over and over again what is postulated as self-evident, to disturb people’s mental habits, the way they do and think things, to dissipate what is familiar and accepted, to reexamine rules and institutions and on the basis of this re-problematization (in which he carries out his specific task as an intellectual) to participate in the formation of a political will (in which he has his role as citizen to play).
That idea of questioning what is allegedly “self-evident” and disturbing people’s mental habits is pretty crucial to testing as a discipline. I would even argue the “role as citizen to play” speaks a bit to the ethical mandate that I talked about in “The Ethical Mandate for Mistake Specialists”.
Yet notice how when people get to be “authorities” — usually by having challenged other authorities before them — they tend to get pretty cantankerous when being challenged themselves. They often like to disturb other people’s mental habits but are less happy when the same occurs to them.
Finally, the “to reexamine rules and institutions” in the above quote is also quite important. On that point, let me switch gears here for a second.
If you teach history — and I have and still do — then one thing you learn is that many students have an understanding of historical thinking as a methodology that’s defined by the consumption of facts. Further, it’s a consumption of facts that were communicated by an authority. That authority could be a textbook or a professor. Those facts communicated by that authority are processed in order to replicate some approved narrative. Specifically, the narrative that the authority has communicated.

That’s exactly what I see in testing over the last decade or so. Testing seems to be gelling around some “approved narrative” of what testing is and how it must be. And it is demonstrably and empirically possible to trace the rise of this “approved narrative” with the decrease in interest of specialized testers and specialized testing by a wider industry. As I said about another point earlier, testers should really be thinking about why that might be the case.
Let me state that another way as a hypothesis that I have put to the test.
If we look at the history — and the empirical data — of how testers have been presenting themselves, i.e., by how and when certain perceptions and framings started in the industry, and if we correlate that with equally public and visible statements by non-testers of how they seem to think of testing coupled with how the industry hires for testing, then there is a very demonstrable trend in how testing is perceived and thus valued.
Now, hold on a minute. Couldn’t it be argued that I’m trying to present an “approved narrative” in this very post? Couldn’t it be argued that I’ve been attempting such a thing through the entirety of my blogging career? Absolutely that could be argued! So let’s keep digging here.
Consensus?
Consider the following:
Certain theories achieve a small, temporary consensus within a mutually reinforcing school of scholarship (often attached to a particular mentor or PhD-producing university department), but only a few basic schemes . . . have achieved acceptance beyond the narrow circles that originated them.
That comes from David Carr in his book The Formation of the Hebrew Bible: A New Reconstruction. Here the “few basic schemes” are what I’m trying to impart in this post and what I’ve tried to impart as my blogging career evolved. This is why I’ve tried to talk about what testing is like rather than provide pronouncements of what testing is as some sort of authority figure.
But I would ask testers in particular: how many of the “basic schemes” of our most ardent test practitioners truly “achieved acceptance beyond the narrow circles that originated them”? Here don’t just look at how testers talk to each other in their echo chambers; look at the wider industry in which those testers are working. Contrast that with the test thinking that has been put forward by developers. Ask yourself which have truly achieved acceptance? I talked about the “asymmetric skew” in my post on the test narrative.
On the topic of religious studies, indulge me, if you will, by considering another extended point:
There seems less point in arguing against an idea whose moment has passed than against one that appears to be on the rise. … This is a worthwhile thing to do not only because we are in the business of understanding the past, including the past of our own field, but also because any attempt to engage sympathetically with superseded ideas makes us humble (our ideas, too, face supersession), while also exemplifying the process of consensus formation . . .
That comes from Seth Schwartz’s article “How Many Judaisms Were There?” and the idea of looking at how consensus formation is taking place within a group of practitioners is crucial. The quote from the above continues on:
It is fundamental that we understand why and how ideas catch on (a process that may owe little to their inherent validity) and then fail (not necessarily because they have been disproved). We can then be more skeptical in our own work about reliance on ideas whose chief asset is that they form part of a local or contemporary consensus.
Exactly! In my posts, I have certainly evolved my thinking. I’ve changed how much importance I put on certain terminology versus others. I have in some cases abandoned lines of thought that I apparently took as extremely important at one point.
My blog has thus been one big, long experiment. And that has taught be to be very wary of pretending I have the answers. I have thoughts. I have conjectures. I have opinions. I like to think many of them are well-formed based on experience. But there is no guarantee I’m correct. That keeps me (hopefully!) humble in how I speak to others about a subject that I’m clearly passionate about.
By extension, that mode of thinking has made me very suspicious of those who try to build consensus or those who claim authority, even when I agree with the consensus view or when I do recognize the legitimate authority of someone based on their body of work or experience. From the same paper as above:
I would like to suggest that one of our goals as professional scholars should be the critique of consensuses, including those formed by our immediate peers and colleagues. Not every consensual view is ipso facto wrong, but once we understand properly the non-cognitive mechanisms that generate them, we are certainly obliged to view consensuses with suspicion. … Critique does not mean blanket rejection, and suspicion does not mean disdain.
Exactly! Let’s hear that part again: Critique does not mean blanket rejection, and suspicion does not mean disdain.
I don’t know that I see a lot of “critique of consensuses, including those formed by our immediate peers and colleagues” in the testing industry. I see a lot of people following relatively few authority figures; often to the point of quoting them extensively. And when there is critique, I actually find much of it to be quite mean-spirited.
All this said, one thing that is without doubt true is that the idea of “obliged to view consensuses with suspicion” is very much a focus of testing and experimentation. It’s a way to critically investigate claims that people are making. Thus in the above we see at least the potential for two distinct fallacies of thinking: the “appeal to authority” and the “appeal to common belief” (or the “appeal to popularity”).
Mind, this isn’t to say that the common belief, or the popular opinion, or the authority is wrong. It’s simply to say that accepting something solely because it’s a common belief, or a popular opinion, or stated by an authority is not in line with an experimentation — and thus testing — ethos.
By the way, when I quote a lot of what seem to be disparate sources, I’m practicing what I’ve referred to in the past as being cross-discipline associative. Good experimenters have to also experiment with their thinking and that often means pulling ideas and thoughts from many disciplines.
The Idea of Causality
Finally, a question that’s implicit in much of the above but should be asked yet often isn’t:
- Do we understand cause and effect?
This gets into the idea of a causal model, which is based on three parts: association (“what if I see?”), intervention (“what if I do?”), and counterfactuals (“what if I had done?”)

In The Book of Why, which I believe every tester should read and from which the above distinctions come from, the author says:
This approach is exceptionally fruitful when we are talking about causality because it bypasses long and unproductive discussions of what exactly causality is and focuses instead on the concrete and answerable question “What can a causal reasoner do?”
I’ll leave it to each individual to read the book to see what the approach being discussed is. But the above highlights my point: don’t talk about what “testing is.” Instead, focus on “what can a tester do?” And in that light, you can ask about what a “human tester” can do versus an “automated tester” or a “scripted tester.”
This is important to me because a lot of testers worry that the phrase “manual testing” is devaluing testers and perhaps leading to social issues like lower pay. That very well may be, if the evidence supports it. I haven’t seen that evidence but I’ve seen the claim quite a bit. What I’m often arguing is: “That may be true. But the counter-arguments that testers provide seem to be having the same effect; perhaps even magnified.”
The above referenced book, if you abstract what it says, more than adequately shows why some of the testing arguments have been failing so spectacularly since 2009 and why specialist testing has struggled in the technocracy when other disciplines have not. I also tried to show how framing against automation at the expense of the human (“manual testing”) can better be done by performing an experiment: look at and understand the history of automation.
The Ethos of Extending Our Reach
So a contention of mine is that a very wide segment of the testing industry is listening to authorities and repeating what they have chosen to accept as the consensus of what “testing is.” And that consensus and those authorities are rarely speaking to a common basis, like that of experimenting, that all should be able to agree with. Or maybe they are speaking to that but it seems to get hidden underneath all that “overcomplication” I mentioned earlier.
But, hold on a minute here. Aren’t I being a bit disingenuous? Isn’t that how a lot of things work? For example, much of science? Isn’t much of science about building consensus, often based on certain authorities?
Yes, although the difference is those practitioners can evolve their discipline by thinking beyond the consensus, particularly in terms of recognizing when the consensus may be accurate but not being communicated very well. Further, those practitioners can actually go beyond the talking points of the authorities they quote. Testers, I often find, cannot. They can quote their chosen authority. But when asked to think about how to do things practically that people need done right now, they struggle a bit more aligning the philosophy they can state with the actions they cab do.
They struggle internally to explain it to themselves and thus they struggle to explain it well to others. This is the insider-outsider problem I talked about as well as possibly having a faulty narrative to begin with.
Incidentally, you’ll notice I reference a lot of what I previously wrote in my own posts. This can seem fairly self-aggrandizing; almost as if I’m treating myself as an authority. On the contrary, however, I do this because that’s how I experiment with my own thinking. I make sure my own thinking is consistent or, if not, I check to see if it’s evolved or devolved.
It’s All About Experimentation
Test specialists, I believe, must be able to think like a specialist historian and thus have some grounding in the study of historiography. When I say that, people might say: “Wait, what? So, to be a tester I have to study history?”
Well, actually, yes, I would argue exactly that. (See my point earlier about the history of automation.) But my point is a bit more nuanced and also more broad.
Experimentation is actually a key part of “doing history.” There are certain key historical thinking skills, which are causality, chronology, multiple perspectives, contingency, empathy, change and continuity over time, framing distinctions between influence / significance / impact, contrasting interpretations of evidence, framing distinctions between intent / motivation, and so on.
All of these unify an approach to “doing history” based on the creation of heuristic fictions (testable hypotheses) that serve as plausible models (disciplined experiments) for historical forces and events (meaningful insights). I try to bring some of these correlations home in “Testing is Like Studying the Past”. (Notice another “is like” rather than “is” distinction.) I also talked about this when I framed testing as experiments around project forces, one of those “forces” being history.
Let’s approach this from another direction. Students often dislike the “show your work” mantra in math. Math is about understanding general principles that guide the behavior of numbers and then applying these principles in a variety of scenarios to generate mathematical solutions to problems.
To reach this ability, students learn the tools, mind-set, and habits of thinking mathematically so that they can then act mathematically — meaning, apply those skills to problems. Those problems may be economic, sociological, socioeconomic, historical, data scientific, computing scientific, actuarial, physics, chemistry, biology and so on.
A key point here is a focus on experimentation. “Showing our work” is a way of saying how we got from one point (a testable hypothesis) to another (a provisional conclusion). That is foundational to testing as a discipline. Testers, like any experimenters, can’t just be mechanics. Testers, like any good experimenter, must understand how knowledge is created.
Testing Becomes a Service
The above was a very oblique way to approach my next and final point.
When we perform testing like this — as an experiment-driven discipline — testing becomes a service.

We don’t so much “assure quality” but we do allow people who have varying viewpoints of what quality means to make informed decisions based upon possible risks.
Those risks usually manifest as degradations as one or another type of quality. Those can be external qualities (usability, accessibility, performance, security, behavior, and so on) or internal qualities (maintainability, scalability, understandability, isolability, extensibility, and so on).
To be a testing service, those who are test specialists apply our technical and social skills to the very best of our ability. We discover the facts about whatever we’re putting to the test (i.e., experimenting upon). We report those facts diligently and dispassionately, making sure that we do honor the knowledge, skills, and feelings of other people, to the extent that this doesn’t compromise our ability to tell them they may be under the sway of illusion or assumption.
We may attempt to diplomatically persuade, particularly when we feel there is a risk that others may be discounting or an illusion in place that we feel must be dispelled. We do this with the understanding that sometimes persuasion fails but diplomacy cannot.

It’s worth noting, again, that in doing all this we are not assuring quality. Instead we are ascertaining the best possible truth about particular qualities that are present or absent in whatever we’re testing.
Quality is a complex tessellation of viewpoints and a shifting perception of value over time. As such, this means quality is, by definition, relational. In our context, that means quality is a relationship between people and whatever product or service we are providing to them and thus has many subjective components. Those people will have differing and varying interpretations of overall quality, individual elements of quality, and how much a given quality is or is not present from their point of view.
Just like in history, the world is not just made up of dry facts sitting there isolated and alone. Any “facts” are really interpretations glued together by relations; by an intricate web of cause-effect relationships. Because of this focus on interpretation, in any discipline that is motivated by experimentation, specialist practitioners must move from simple “processors of data” to “creators of explanations.” Those explanations are an interpretation of truth that we ask people to trust.
Experiments are about helping people decide what they can have trust in. It gives people an objective way to have trust even among that which has subjective components, like quality.
Why? Because the explanation provides a narrative. And narrative is rooted in cause and effect. And cause and effect are eminently subject to investigation. Ambiguity, inconsistency and contradiction — all enemies of quality — can be ferreted out by subjecting cause and effect to analysis.
Sometimes we run into paradoxes.
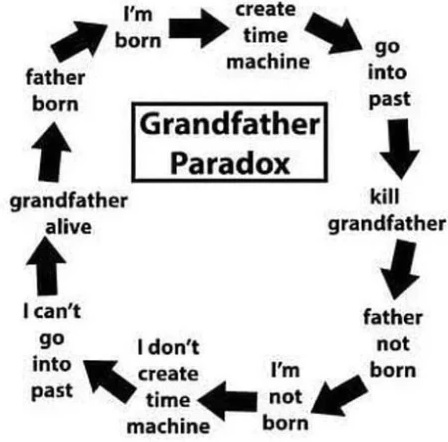
Paradoxes represent situations where our causal intuition seems to be flawed. These moments and situations — which experiments uncover — provide us a way to “reverse engineer” that intuition, by reducing it to smaller bits, each of which can be subjected to experiment. This let’s us look at the “shape” of what we’re talking about.
This allows us to work with a smaller surface area of thinking problem so that we are less subject to wide shifts in categories of error around how we think. This is quite similar to how we modulate scope on our technical projects so that we have less surface area for bugs and regressions.
Experimentation is Foundational
I believe what I said in this post regarding experimentation as the basis for testing is pretty foundational to anyone who wants to think about testing as a discipline and as a craft within our industry. If there is anything that we can start with as a common basis for being authoritative and being a point of unanimity, I would think it is this.
We can all debate whether “manual” should be applied to “testing.” We can all talk about differing categories of testing. Good recent examples I’ve heard are “instrumented” and “experiential.” But all of that is still, I would argue, subordinate to the above.
Testers need to make sure they understand the principles behind good experimentation, understand how to create explanations, and understand how to communicate this same style of thinking to whatever group or company they are working with. If they don’t, all that other terminology and all those other distinctions are effectively not useful.
I believe with a common foundation in place, we can then have healthy discussions about the wider ambit of our work without the mean-spiritedness or the appeals to popular belief or the stridency of a particular authority. That should be part of our ethos to each other. Without that in place, our ability to communicate testing to others — and thus to effect change in a growing technocracy — is likely to be compromised.

Enjoyed your thoughts. In my experience, the management layers between the scientifically precise and the visionary champions of the business are both the problematic machinery and, ironically, the hiring managers for projects. O would that more articles like this served to inspire and educate those of us caught in the middle together.